
Bias, Bias All Around
What's in your data?
The hype cycle for artificial intelligence is starting to fade a little bit. The gold rush is still on, but the perception of “AI = magic” is gradually facing the business realities of imprecision, inaccuracy, and bias – the same issues facing machine learning and prediction from before the generative AI bubble.
Speaking of bias, this article is just another nice reminder of the under-appreciated foundational issues with the data underpinning so much of the apparent magic. These authors use, as their exemplar, public image data sets for fetal ultrasound – and give a nice summary of problems they propose in the combined data sets available for training:
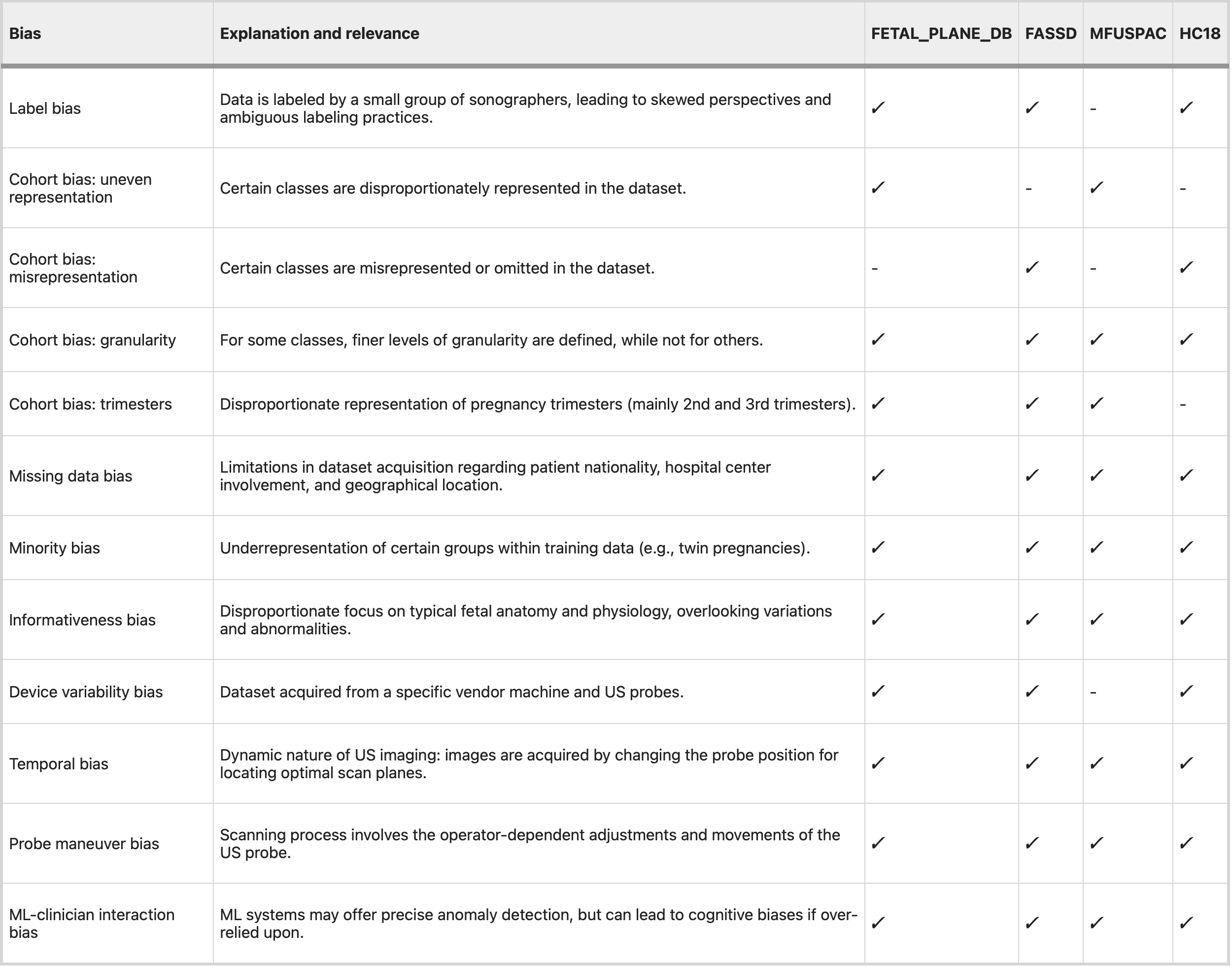
As you can see, the issues identified are basically omnipresent – and, likely, not dissimilar from other data sets in medicine. There ought be no question regarding the importance of external validation and prospective monitoring of models and AI tools in medicine.