
Can The Chatbot Run Your EHR?
Roam free little agents!
Where our friends in business have found their workflows increasingly automated by agentic minions, and bland production software engineering has become the domain of AI – can we sprinkle some of that on the EHR?
This is PhysicianBench – a suite of tasks created by researchers at Stanford requiring LLM-based clinical agents to execute sequential series of tasks mimicking those performed by clinicians in their daily work. This is a step forward beyond prior measures such as HealthBench, AgentClinic, EHRAgent, MedAgent, etc. in that it uses 1) a live EHR environment, 2) multiple chained tasks, 3) a framework for verification, 4) and based on tasks validated by clinicians in 21 specialties.
These look roughly like:

And the entire library is up on their GitHub.
There’s a pretty little graph:
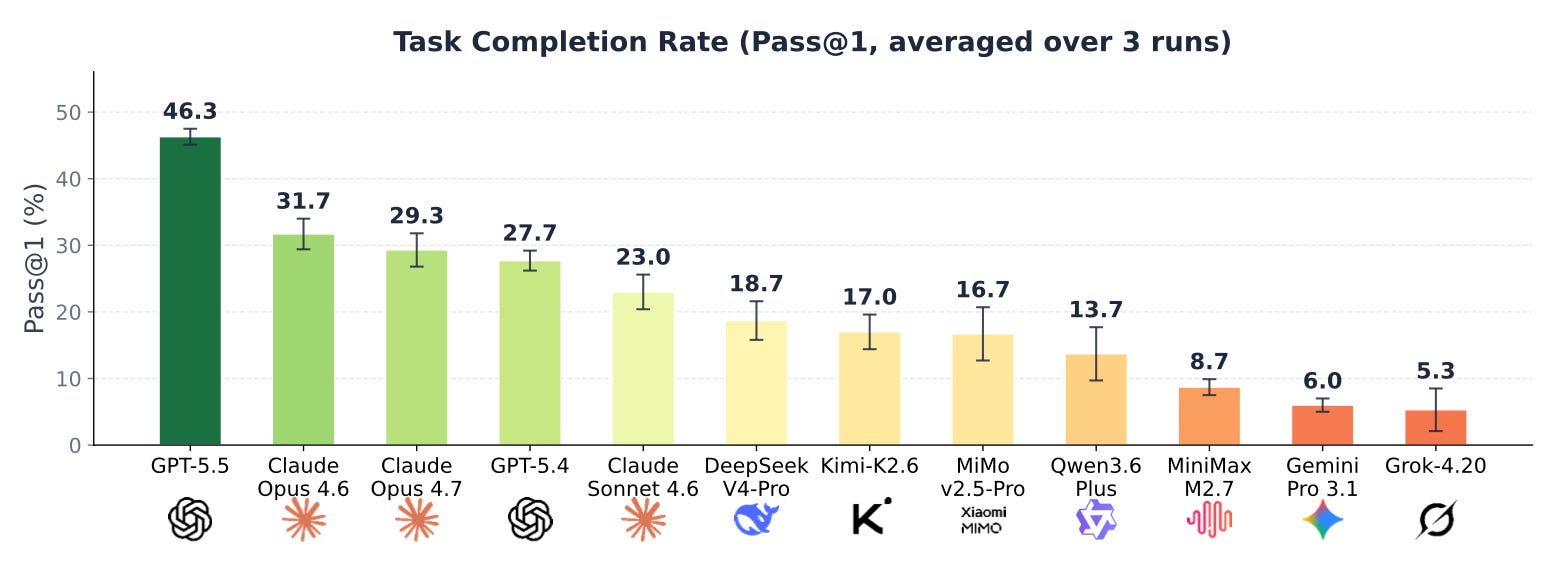
Which shows GPT 5.5 was their top performer, completing approximately 46% of the tasks within their benchmarking library.
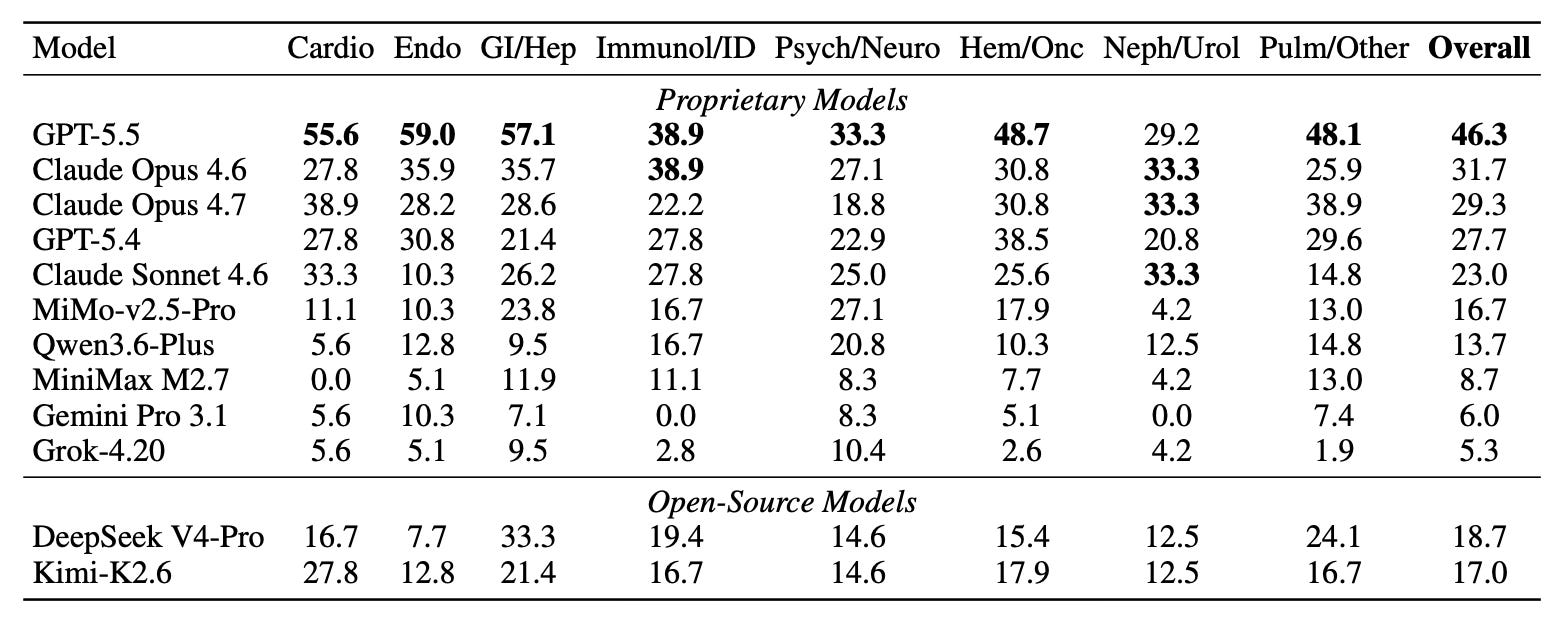
And then there’s so much fun in the paper – for example, are certain specialties more challenging than others?
And at what point in the tasks are the models crashing out?
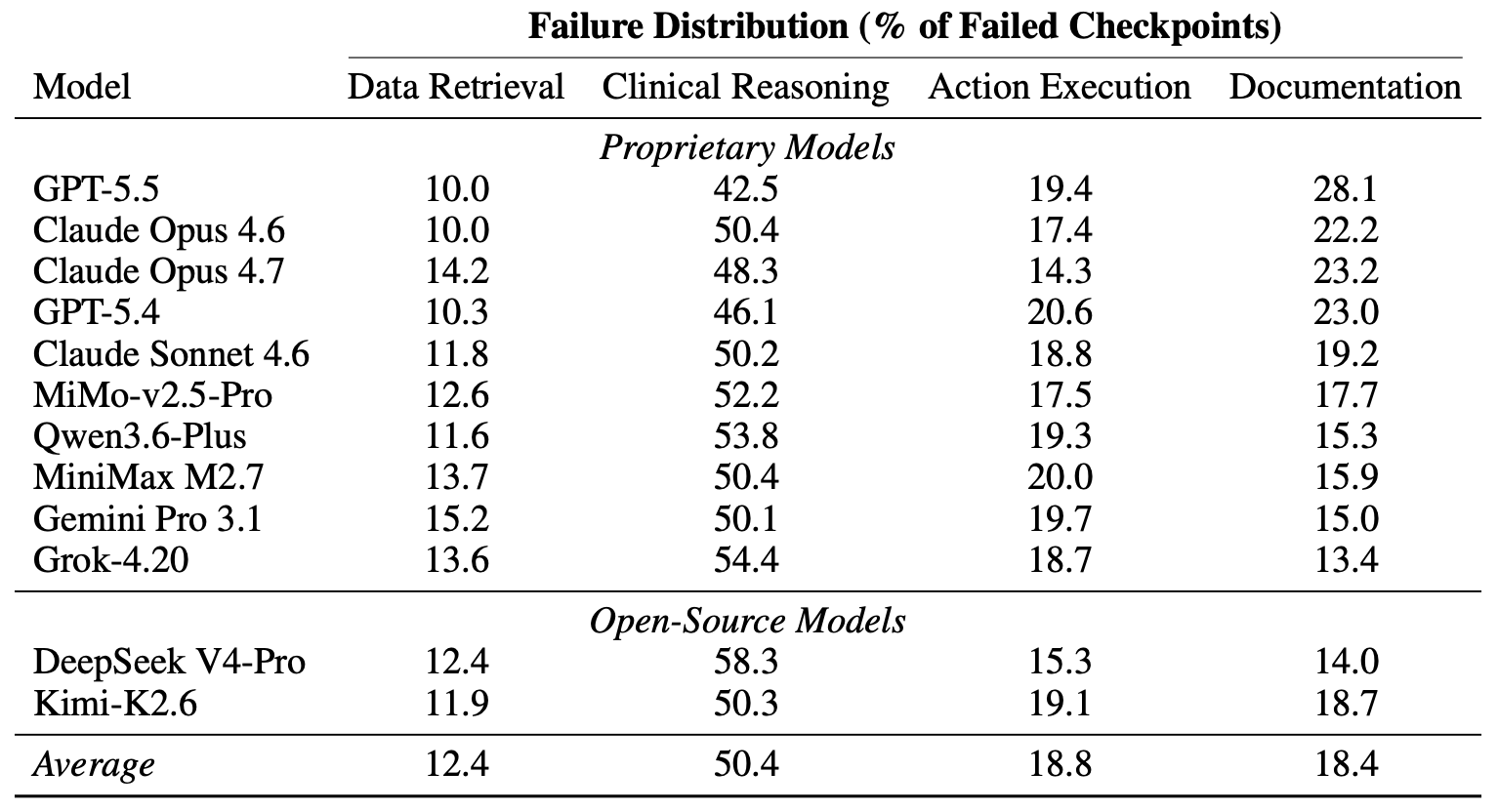
Now, there can always be quirks in the construction of the test environment putting the thumb on certain models versus others, but the results have gross face validity. Then, these are not “physician replacement”, they are just taskrabbits – and these are general models, not versions designed to execute clinical tasks. So, we’re not quite at reliable problem-solving minion level, but likely only a few generations away.