
Humans + LLMs Can Crash & Burn
Average humans are not quite the power users physicians might be.
As we’ve repeatedly seen, there’s a line of evaluation pitting LLMs versus humans and LLMs versus humans + LLMs. However, most of these simulated clinical tests utilizing humans are doing so with physicians at the controls, drawing upon their knowledge and experience to frame the prompts to drive responses from the LLM.
In contrast, the overwhelming usage of LLMs for medical purposes is not by clinicians – it’s from your everyday average consumer. There is a hetereogeneous scope of medical knowledge among the general public, but it is safe to assert this knowledge is likely inferior to that of a clinical professional. This means you’ll likely end up with very different conversations with the LLM over the same health domain or clinical context.
This is a fun and insightful study that grossly tests the degradation in LLM utility when driven by an average human, as compared to a clinician. In this study, a panel of clinicians created case descriptions for ten cases, along with a consensus of likely diagnoses and appropriate triage advice – ambulance, emergency department, urgent care, etc. The authors fed those clinical cases to three different LLMs and scored their responses. Then, the authors gave those same cases to non-medical consumers to “role play” the case to the LLM, and again scored those responses.
The [2024] LLMs did pretty well with the full case information – but dramatically worse when driven by an average human:
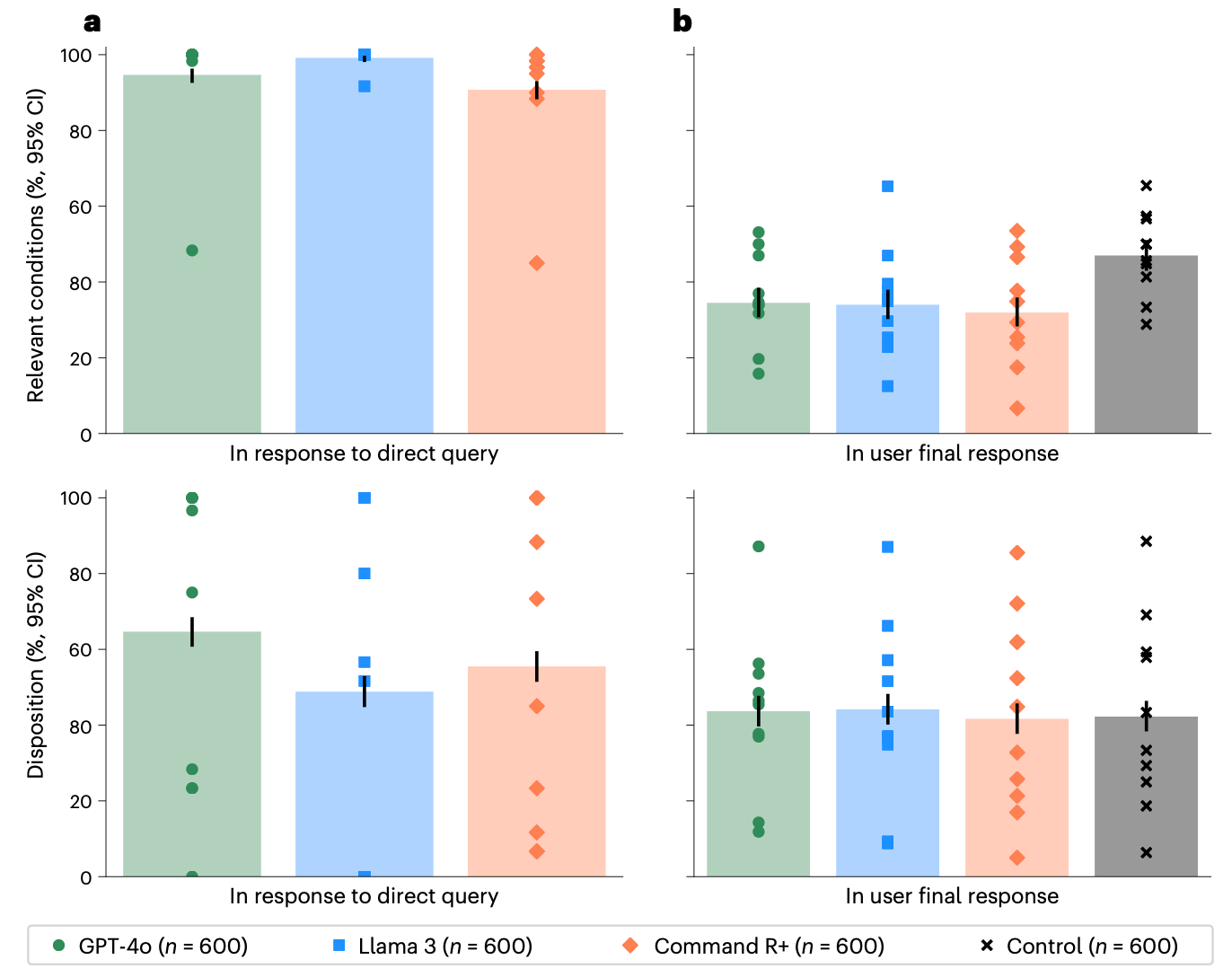
Human users elicited far fewer accurate diagnostic responses, and, as a result, the advice from the LLM – well, it was not great to start, and then worse again.
I think there are a lot of folks looking at offloading cognitive and diagnostic tasks to public-facing LLMs based on well-controlled demonstrations of clinical performance, and the reality is likely far more fraught. This study used off-the-shelf models for testing, and health-specific configurations may have information mapping and gathering mitigations, but these findings raise important questions to be answered.