
LLMs Are Still Full Of Health Misinformation
... but so are traditional search engines.
It’s popular to bash the flagship LLMs for the various inaccuracies uncovered during routine use. As “smart” as they seem, with their “reasoning”, they’re still just a product of their training set – so, garbage in, garbage out.
However, there is a defense for these malfunctioning LLMs: the refuge of the “best available alternative”. For example, in testing LLMs on some clinical diagnostic tasks, it is worth recalling many healthcare settings have inadequate access to clinical specialist support. In that sense, even imperfect retrieval from an LLM may still have value.
In a similar vein, this study tests LLMs on 150 health-related questions from the “TREC Health Misinformation Track”, and compares their answers against the answers a hypothetical user would obtain if they used common web search engines.
First, the LLMs – split up into questions with “no context”, questions framed as coming from a “non-expert”, and questions incorporating prompts asking the LLM to take on the role of an “expert”:
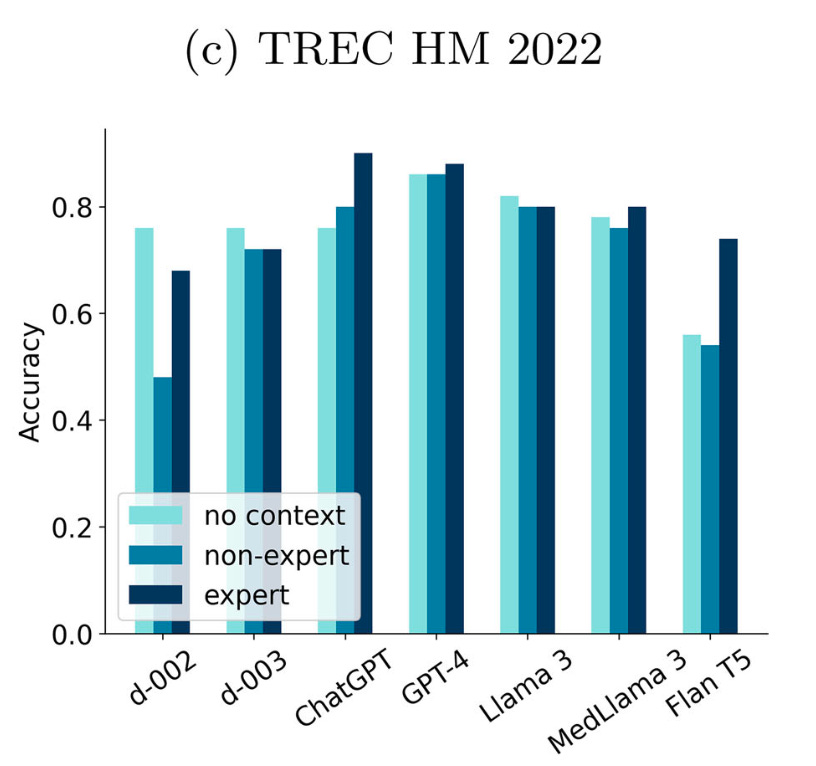
As you can see, the flagship models – GPT-4 and Llamas – are around 80% accuracy.
Now, the web search – split up into “lazy user” (takes the answer from the first valid search result) and “diligent user” (checks three sources and takes the majority answer):
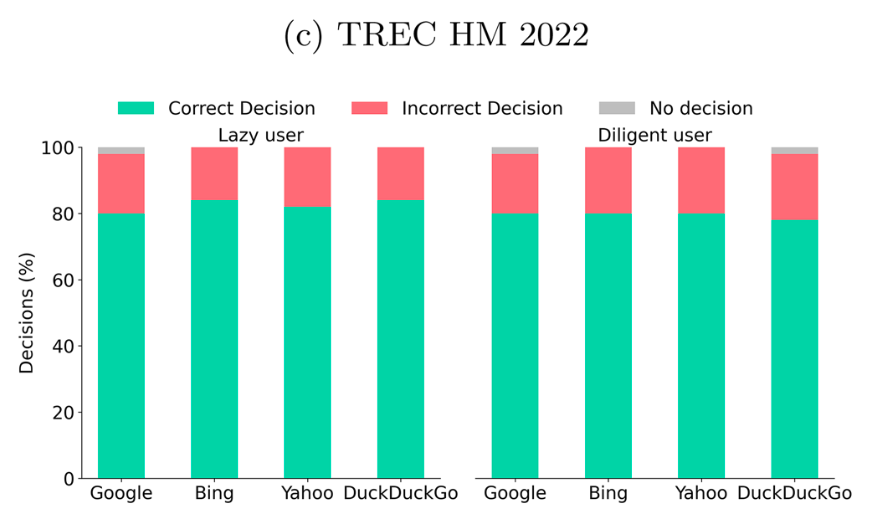
So, here we are again – around 80%, and, amusingly, just as good if one is “lazy”.
There’s obviously a lot more detail in the manuscript itself, including some variations on LLM use with retrieval augmentation and more details on the types of errors. However, the overall point remains – the crap found in LLMs is simply representative of the garbage ingested, the garbage content you’d find with a typical search engine. Fix the training set, and you’ve taken a big step towards fixing the LLMs.