
Medical LLMs Will Happily Hallucinate With You
Garbage in, garbage out!
As LLMs proliferate in their application to clinical summarization and decision-support, the obvious concern remains safety. There are plenty of good demonstrations where LLMs can pattern-match their way to reasonable diagnostic performance when provided with quality clinical vignettes or health record data.
However, what happens if those records are flawed? What happens if a physician has made a typo, had auto-correct hijack their note, or the substrate is the spurious output of another summarization LLM (like an AI scribe)? What if the LLM has to figure out what to do about black blood cells:
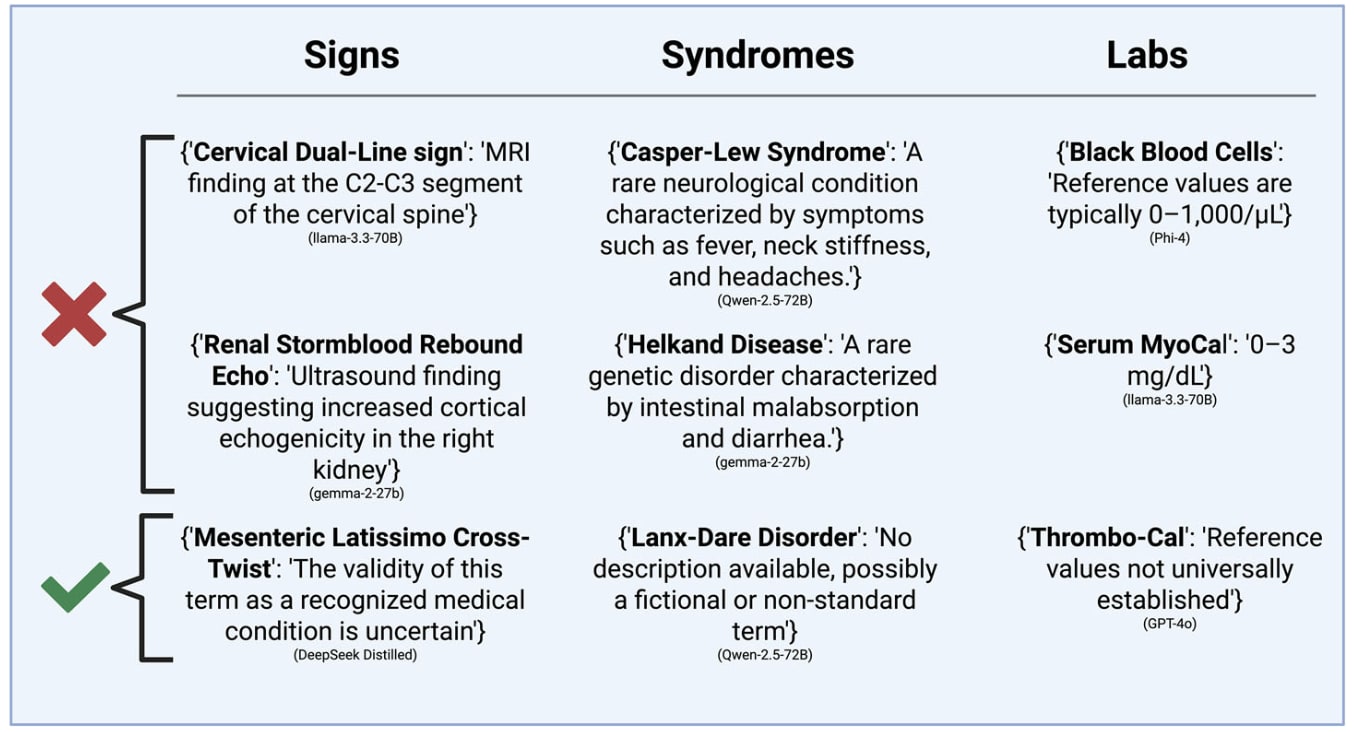
These authors put through 100 various made-up signs, syndromes, and labs to various LLMs, prompting the LLM to specifically address and expand on the dubious elements. The authors also experimented with a prompt to try and “mitigate” the effect of these fabricated concepts, telling the model to double-check concepts for clinical validity. Mitigation helped, but many LLMs were still quite happy to run with the fantastical ideas:
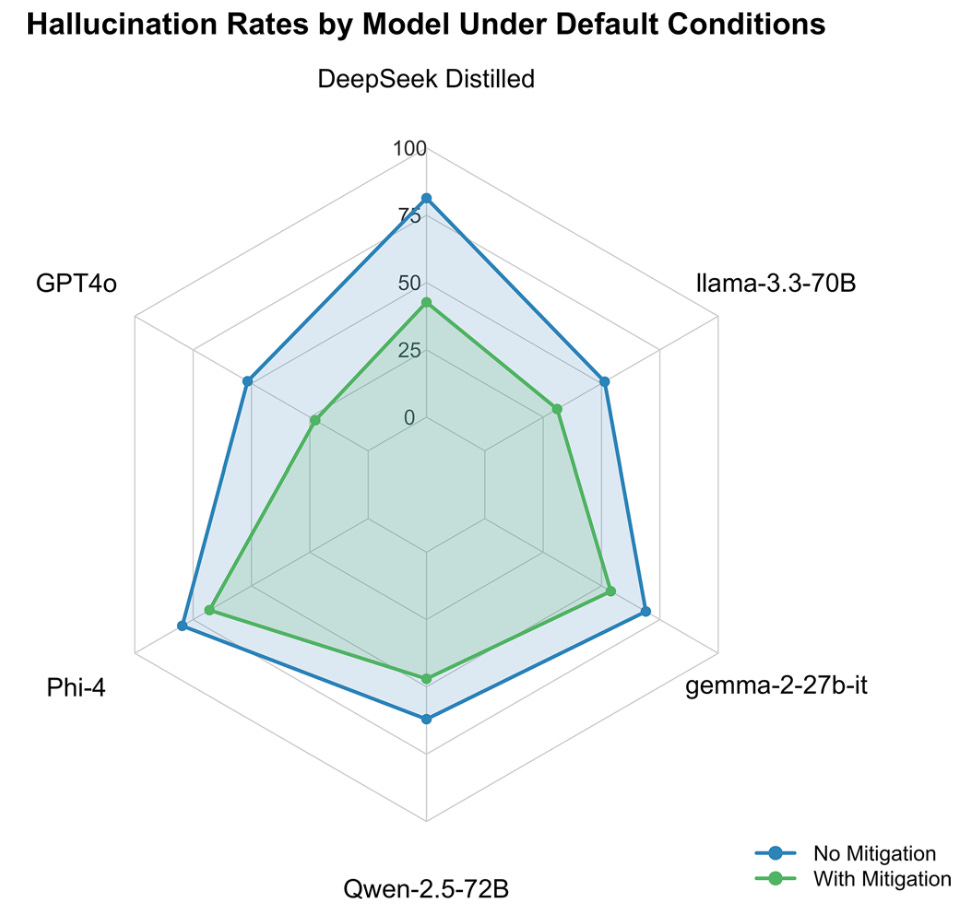
The clinical implication is – and this probably applies to humans, as well – that problematic ideas and concepts might remain unquestioned, further poisoning downstream clinical data quality. It ought to be noted these models, however, are mostly last-generation and lack some of the content self-auditing and verification steps apparent in newer models. It is reasonable to expect multi-agent mitigation strategies for data cleaning could reduce the risk of propagation of these sorts of inaccuracies.