
OpenEvidence, The Ten Billion Dollar Chimera
Is it better, or is it branding?
If OpenEvidence is to be believed, its medical LLM is special. The company has relationships with knowledge vendors, partnerships with specialty societies, and a suite of integrated tools. But, the defining feature has been the LLM, tucked behind clinician-specific gatekeeping.
What if – however – it turned out the LLM wasn’t better?
What if it was no better than the obsequious Google AI result that comes with search?
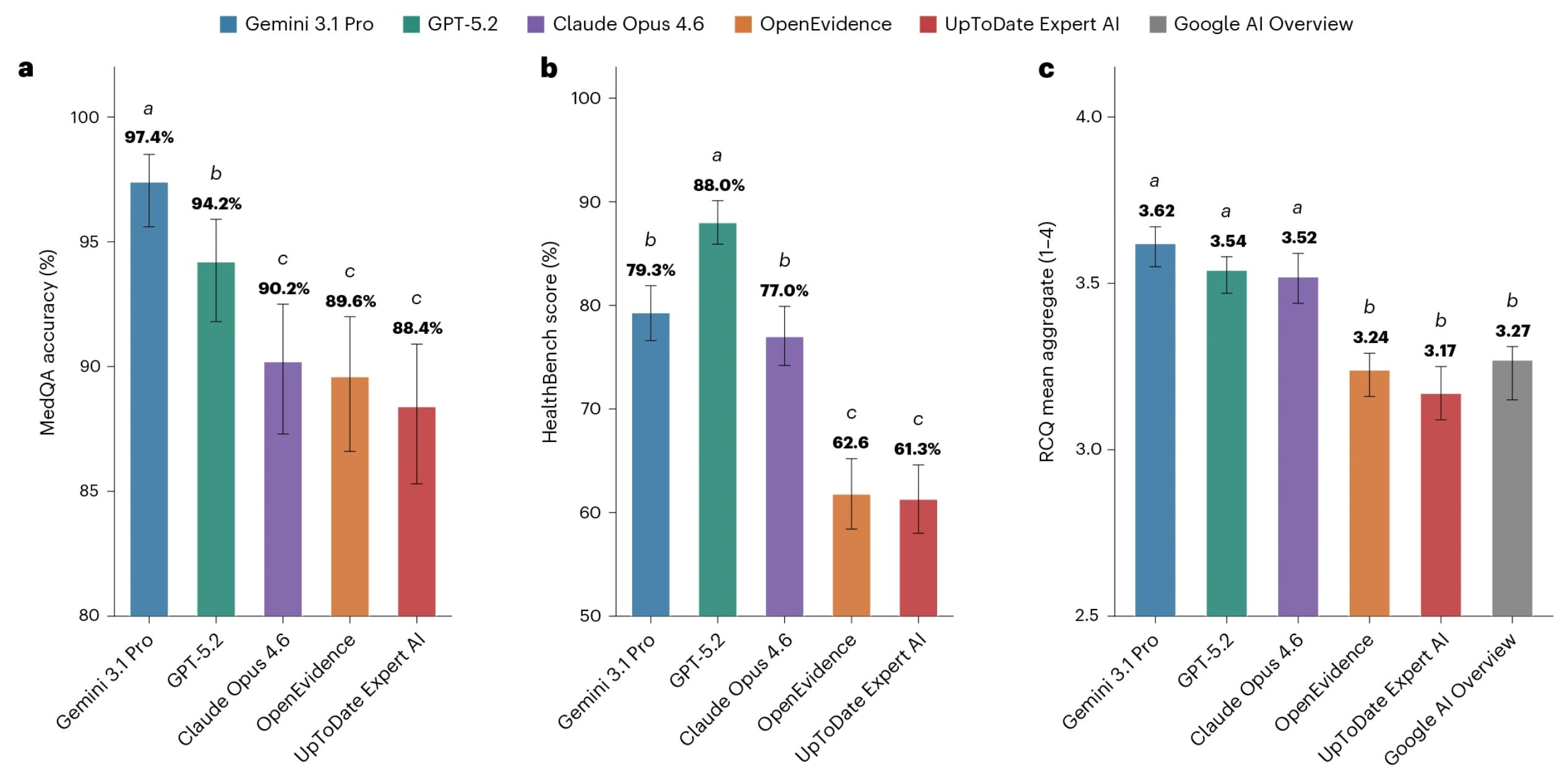
That is the general gist of this brief communication, a trial of multiple frontier models against the current heavyweights of medical reference: OpenEvidence and UpToDate AI. Whether it’s MedQA (a), HealthBench (b), or Real Clinical Queries benchmark (c), the frontier models are on top:
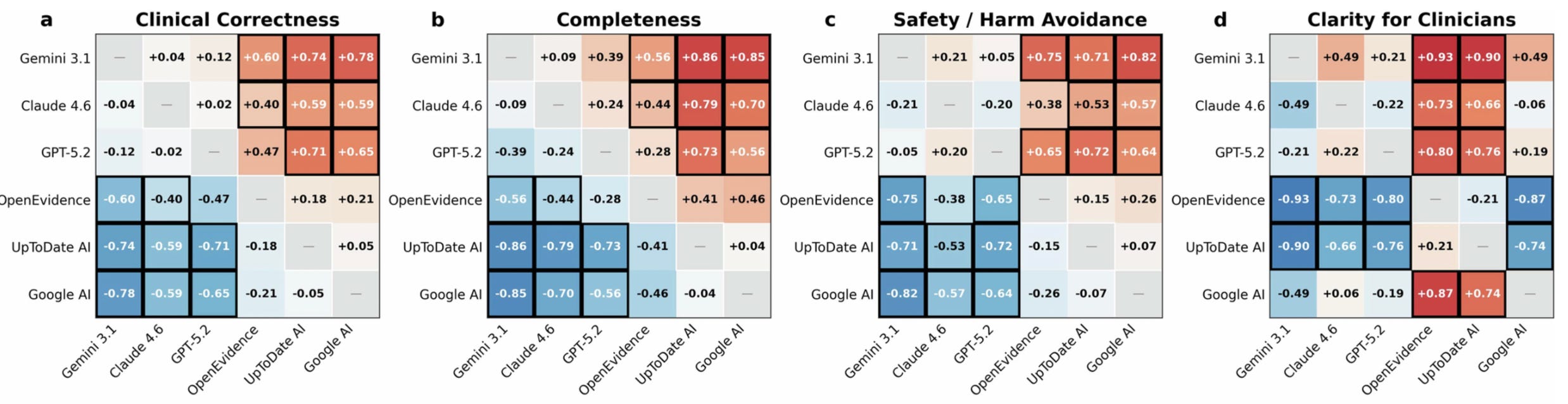
Specifically, where they had real clinicians review the outputs from Real Clinical Queries benchmark, it is obvious the general models have it covered in all the pairwise comparisons:
And, naturally, any publication involving “frontier LLMs” – showcases performance of models already obsolete in present day!