
Popping The Hood on LLMs
A good reminder there isn't "intelligence" beneath their "intelligent" outputs.
This is a fascinating (and long!)(but easy!) read through a report from Anthropic, the makers of the Claude LLM. What they’ve done is, effectively, create a neural network similar in construction to LLMs, but with the ability to examine which parts of the training set are most strongly represented within a response to a prompt. Better still, the authors developed a technique to up-regulate or down-regulate specific features within a response, showing how different features propagate in tasks requiring apparent “planning”.
For example, creating rhyming poetry and the need to “plan” the end of the next line prior to generating the tokens:
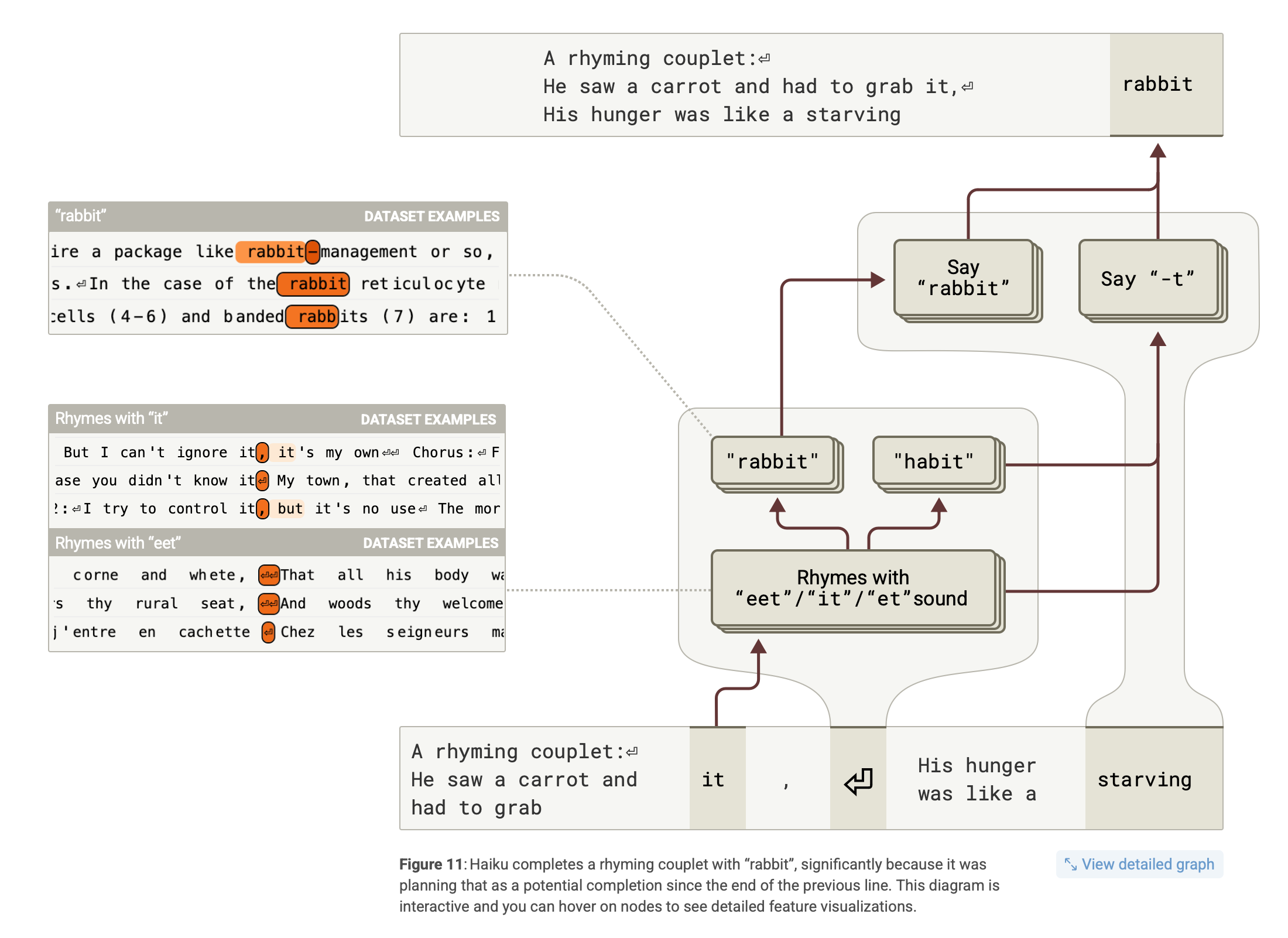
And, there’s an entire section looking at the feature recognition powering medical diagnosis and completion prediction:
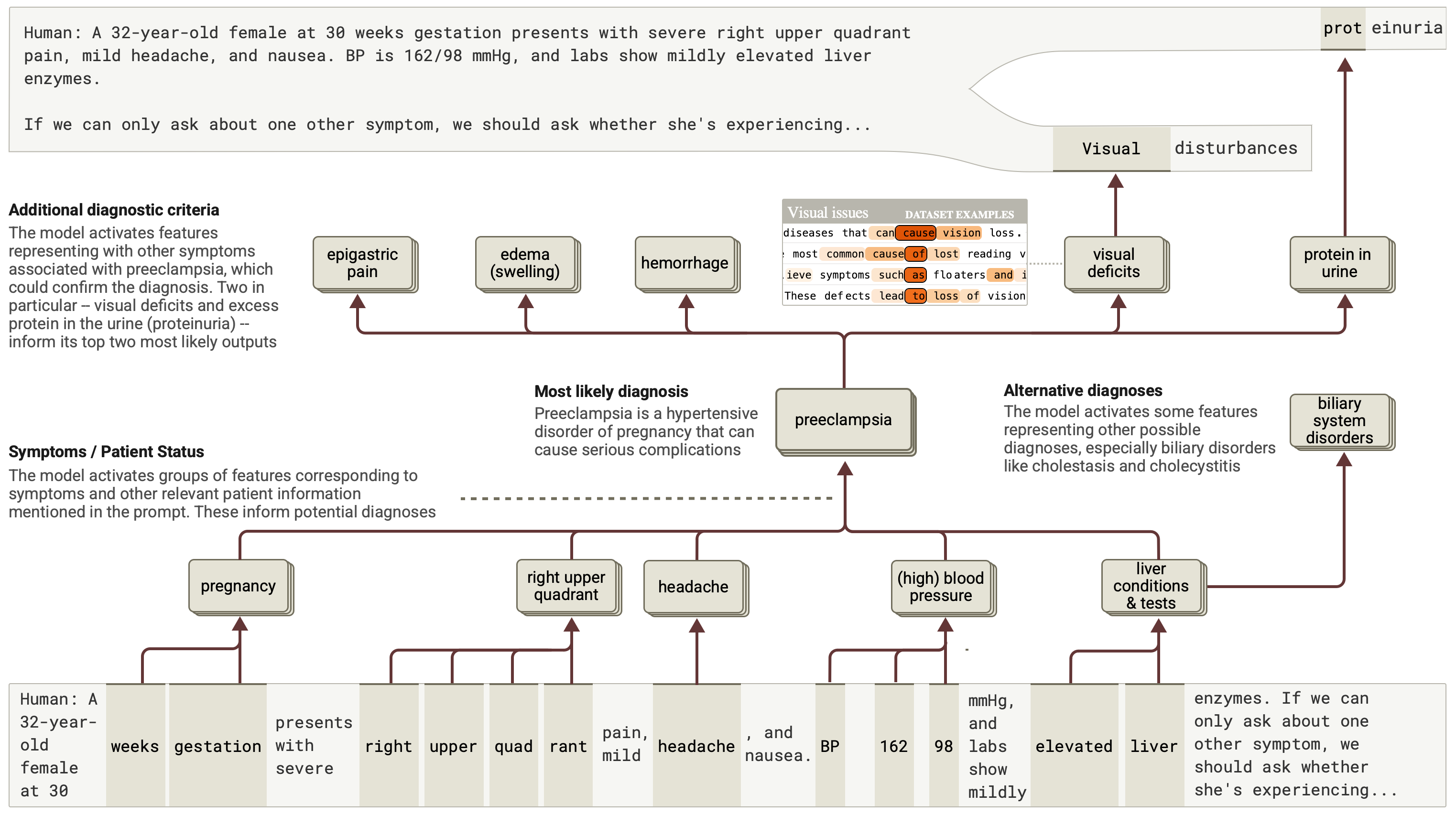
So, if you’ve ever wanted to know how an LLM “thinks” – which can be quite important when considering how to get the best output – this is an excellent read. There’s some bias here with a soft touch towards LLMs painting them as friendly assistants, as you’d expect from a purveyor of such technology, but the insight outweighs such concerns.