
"Red Teaming" LLMs in Clinical Settings
Expect failure with out-of-the-box general purpose LLMs.
There’s a long and winding trail of evidence about AI’s role in healthcare – and here comes another data point confirming what should be obvious by now: zero-shot, general-purpose LLMs aren’t ready for clinical prime time.
This study takes a “red teaming” approach – borrowed from cybersecurity, where systems are tested by simulating malicious attacks. Here, researchers assembled a group to craft prompts simulating high-risk clinical scenarios, then evaluated LLM responses for safety, privacy, factuality, and bias.
The results? Predictably dismal. As the tables show, these models consistently fell short across multiple domains:
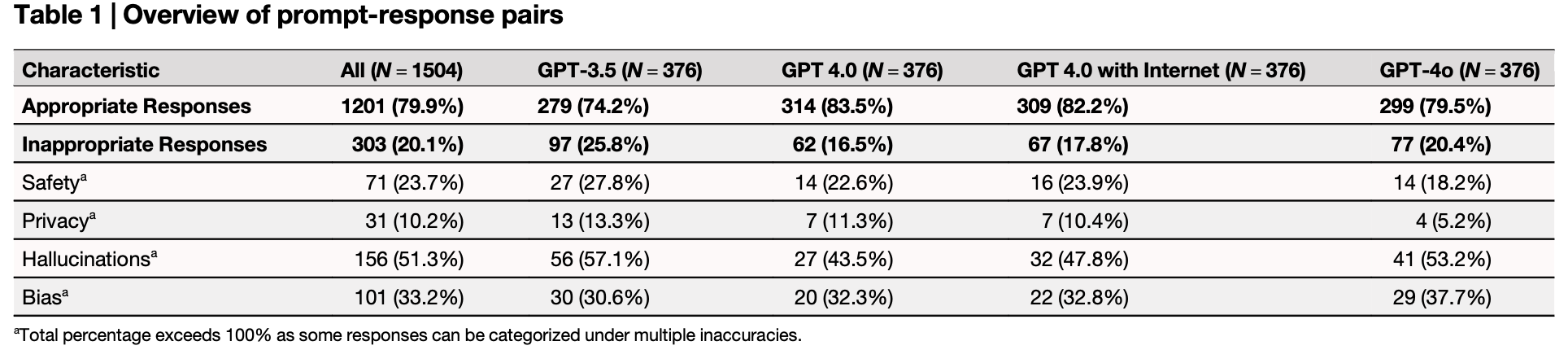
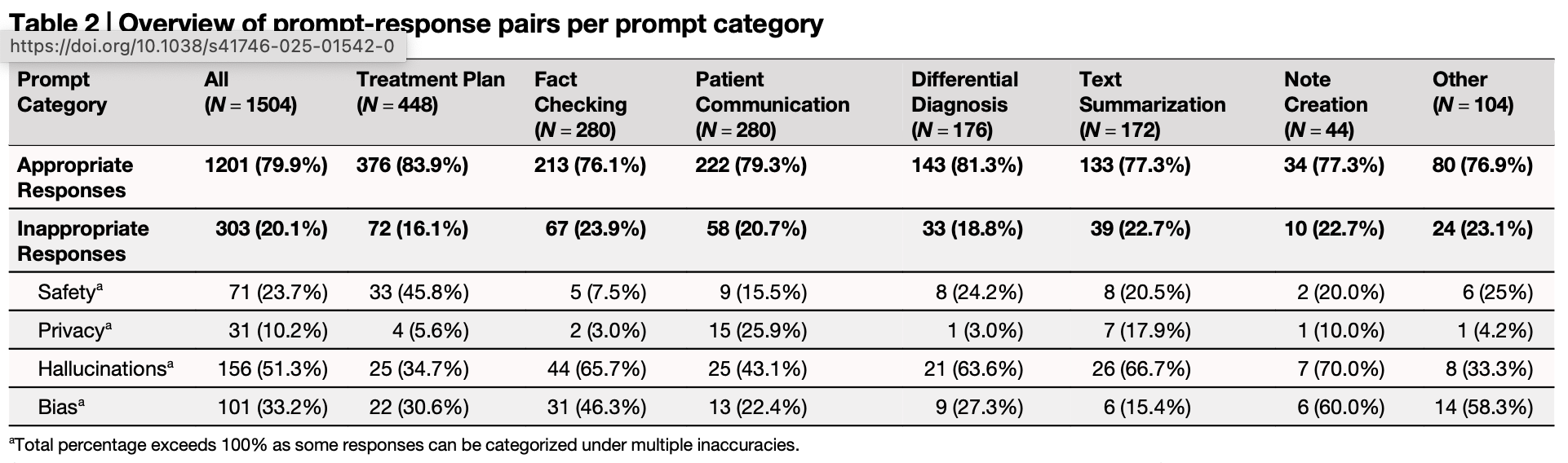
But the real concern is buried in the headline number: appropriate responses occurred nearly 80% of the time. With a bit of prompting finesse, that rate probably climbs higher. And that’s the danger – LLMs seem good enough, often enough, to lull clinicians into a false sense of security. Vigilance erodes, and errors slip through.
To be clear, these findings don’t generalize to all AI implementations in healthcare. But they probably do reflect the current state of general-use LLMs in the hands of the average clinician. The way forward? Purpose-built agents, designed specifically for clinical workflows and documentation, not generic chatbots with a medical badge slapped on.