
"Small" Language Models For Medicine
Training, not size, for the win.
Moore’s Law describes the steady march forward in the number of transistors crammed onto a chip, mostly as a surrogate for advancing performance. More transistors, better results. The same tack has been generally applied to frontier Large Language Models – more parameters, better responses.
However, in microprocessors, additional transistors do not necessarily require more power – otherwise the power requirements of personal computers would be doubling every year. With LLMs, however, there are a lot of energy and computational time costs associated with increasing size.
This little piece is a bit of a demonstration regarding the “Meerkat” series of language models, an example of training and fine-tuning “small” language models based on 7B and 8B parameter open-source models. In this instance, these authors performed their training by “generating high-quality CoT data from a question-answering (QA) dataset, augmenting this CoT data using medical textbooks, and reusing/repurposing pre-existing instruction-following datasets covering various medical use cases with suitable modifications.” Some of these are straightforward content digestion, whereas others required other LLMs to generate training content.
The performance of the Meerkat models slot in as below:
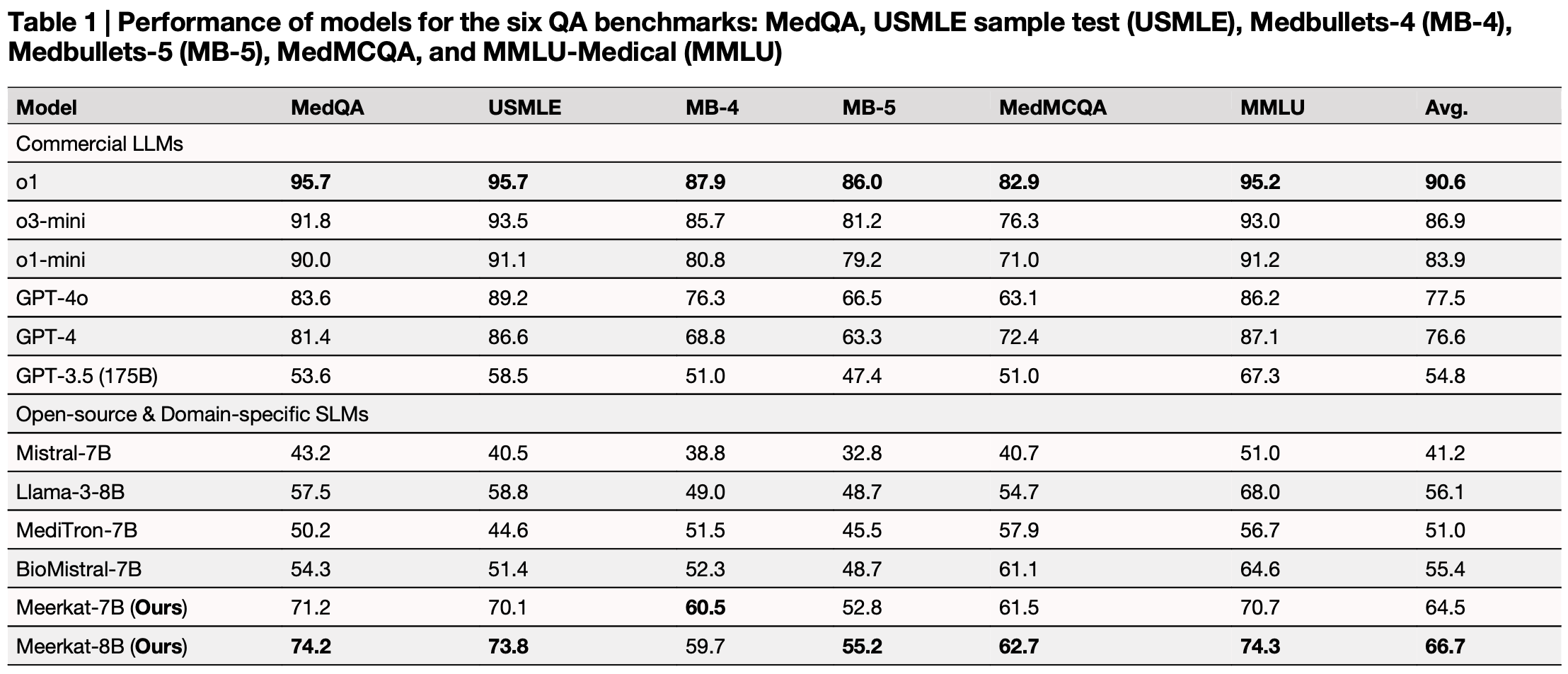
The purpose of their demonstration is primarily to show their advances against the remaining suite of off-the-shelf 7B and 8B models, but it can also be seen it generally outperforms the 175B parameter GPT-3.5.
This isn’t necessarily a “let’s use Meerkat” post, but moreso a demonstration where the gains to be had in LLMs – at least, the gains feasible without torching the planet – need to come partly from improved methods of training rather than just adding parameters.