
Sweeping Concept Harmonization Under The Rug
Structured and labeled data is so passé.
One of the most painful data science problems out there is concept harmonization between health information systems. The “hey, let’s pool our hospitals’ clinical data for Science!” sounds great until you realize entries in a flowsheet measure different data, despite having the same label. Or, the same measurements have different labels. Or, many other permutations of fuzzy non-equivalence.
So, instead of doing that hard work to create high-quality data – why not just yeet those tables of structured data back into free text and let a transformer glean its “meaning” en route to a black box prediction?
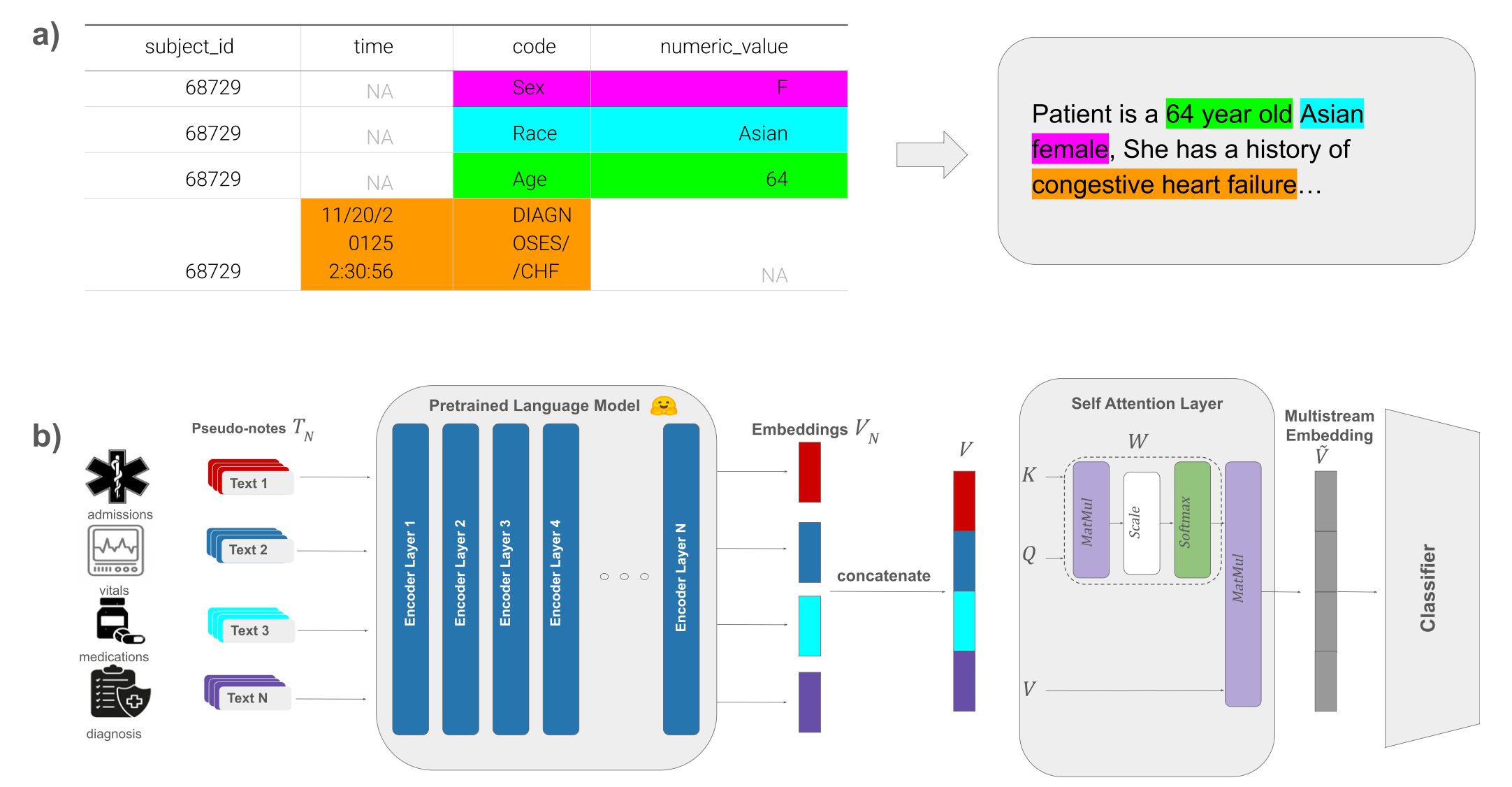
“Why not” indeed:
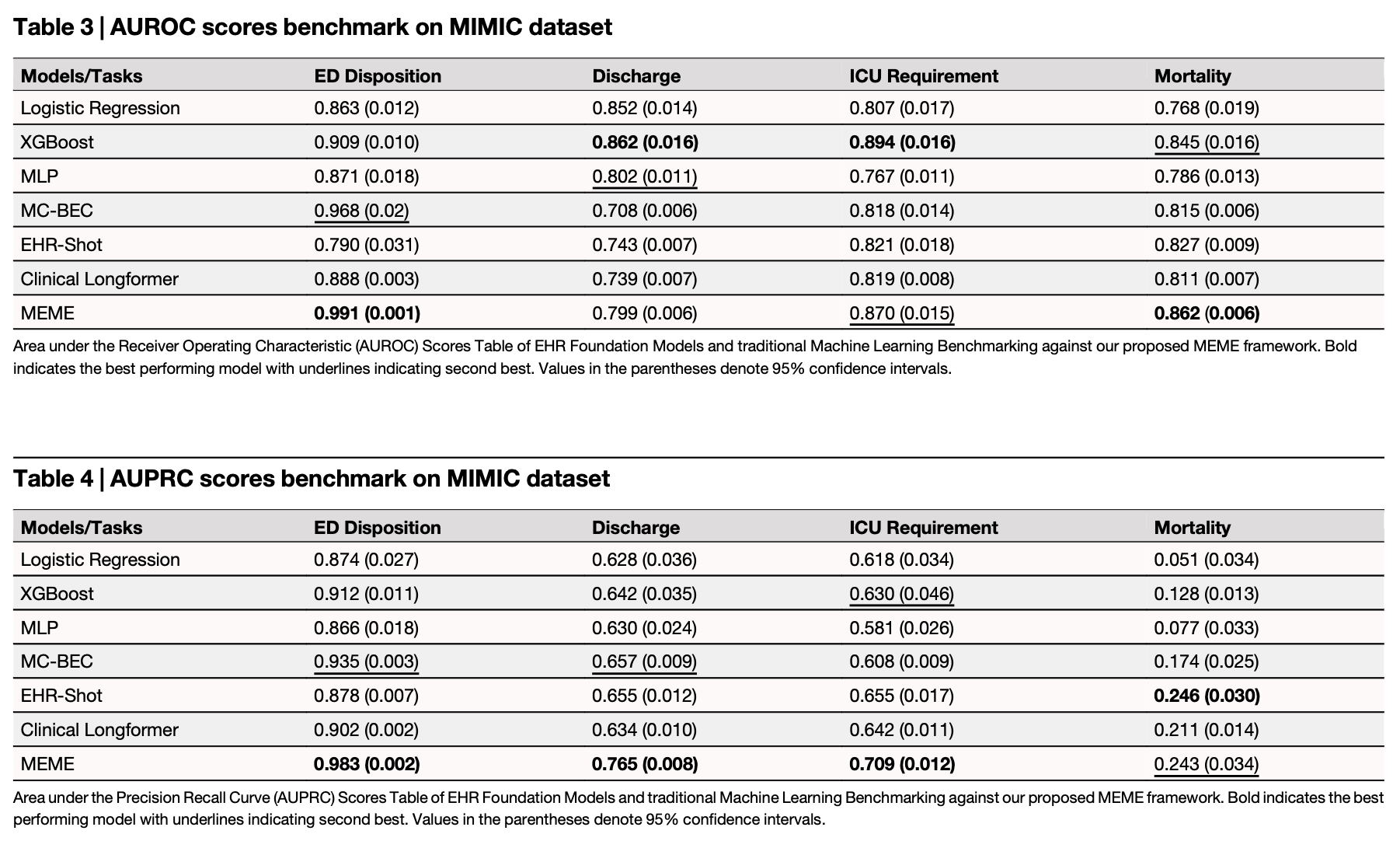
The authors put their “MEME” bespoke transformer model architecture up against several other older ML methods, as well as a few other domain-enriched LLMs, and it manages to pull off the best performance on the age-old MIMIC dataset.
It’s a mildly novel solution to a thorny problem, even if it makes many informaticians recoil in horror.