
That Citation Doesn't Say That!
Did you even read the article? Or is there another motive ....
Every so often, I’ll read an article and find a sentence setting out a claim that appears specious. Sometimes there’s a citation – and many times, it’s a paper I’ve previously read, and I know it says nothing of the sort. Other times, I have to go pull the reference myself – ideally to update my own knowledge as much as to check for an error.
These authors perform an analysis of a sort I’ve not quite seen performed systematically before – an automated analysis of citation “fidelity”. They developed methods of identifying content pairs between the citation in context and the content of the referenced citation.
Here’s a fun figure from their article:
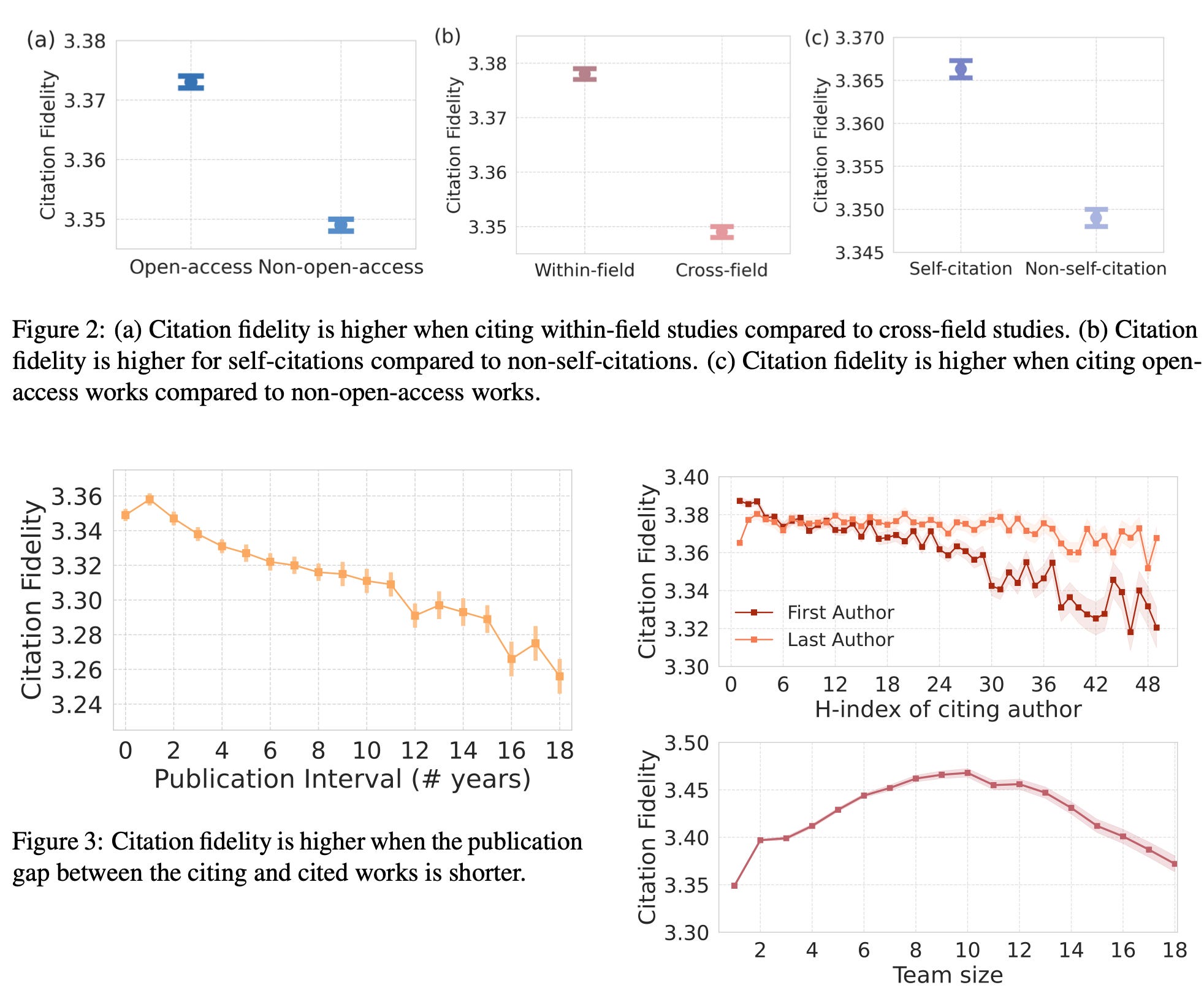
Based on their analysis, they found several patterns as to which types of citations were more- or less-likely to have mismatched a reference. Some seem to have reasonable face validity: open access, citations within the author’s field, citations nested within citations, etc.
The authors don’t try to count the mismatches or perform any sort of validity check on the integrity of the works involved. And, as you can see from the figure, the compression on the y-axis exaggerates the tiny (but “significant”) differences they found. It’s not earth-shattering and the methods may prove a bit “inventive”, but it’s a fun approach to peruse.