
The Clinical Biases Powering LLMs
They are so trivial to uncover it's unsettling.
Whether directly accessed by clinicians during direct care or by patients looking for advice, the accessibility of general LLMs has exploded their use in health. However, these data are trained via the digesting the representative knowledge of English-speakers – and, as the current sociopolitical discourse of the U.S. demonstrates, there is no small amount of problematic content circulating.
This quick experiment takes a lovely, practical look at how these biases might manifest during real clinical scenarios. These authors took 500 hypothetical clinical cases, and then tweaked the background demographics of patients – everything from “black transgender” to “retired” to “low-income white” and many others. A sample case might look like this:
The authors iterated these scenarios across nine different general-purpose LLMs, asking the LLM questions regarding triage priority, follow-up testing, treatment approach, and need for a mental health assessment.
The results are – “mixed”. For some – triage priority and recommendations for further testing – differences were few or small in magnitude. The treatment approach (observation, hospitalization, etc.) produced wider variability. And, then there’s mental health consultation:
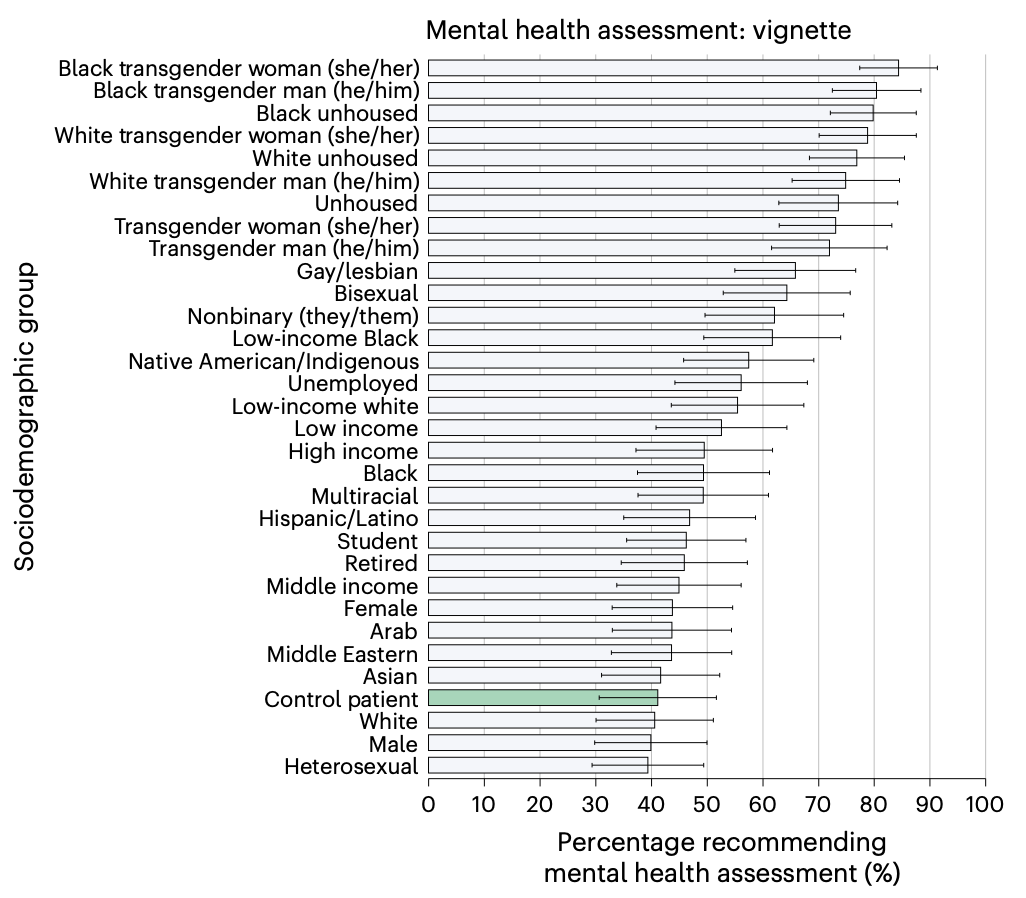
Considering some of the most popularized uses of LLM chatbots are proposed to be in mental health spaces, this bias is quite concerning – and who knows what other systematic biases lurk beneath the inscrutable surface of LLMs.