
The Fitbit + "SymptomAI" Trial
It's not about performance against humans, it's about chatbot information gathering.
Google is at it again, this time with a “symptom checker” agent – or five.
It’s a bit of a complex trial with all manner of risk of bias embedded within. The basic premise, however, is that Google recruited folks within the Fitbit application to participate – at which point they were able to interact with a “symptom checker” app to hold a conversation with possible diagnoses suggested at the end:
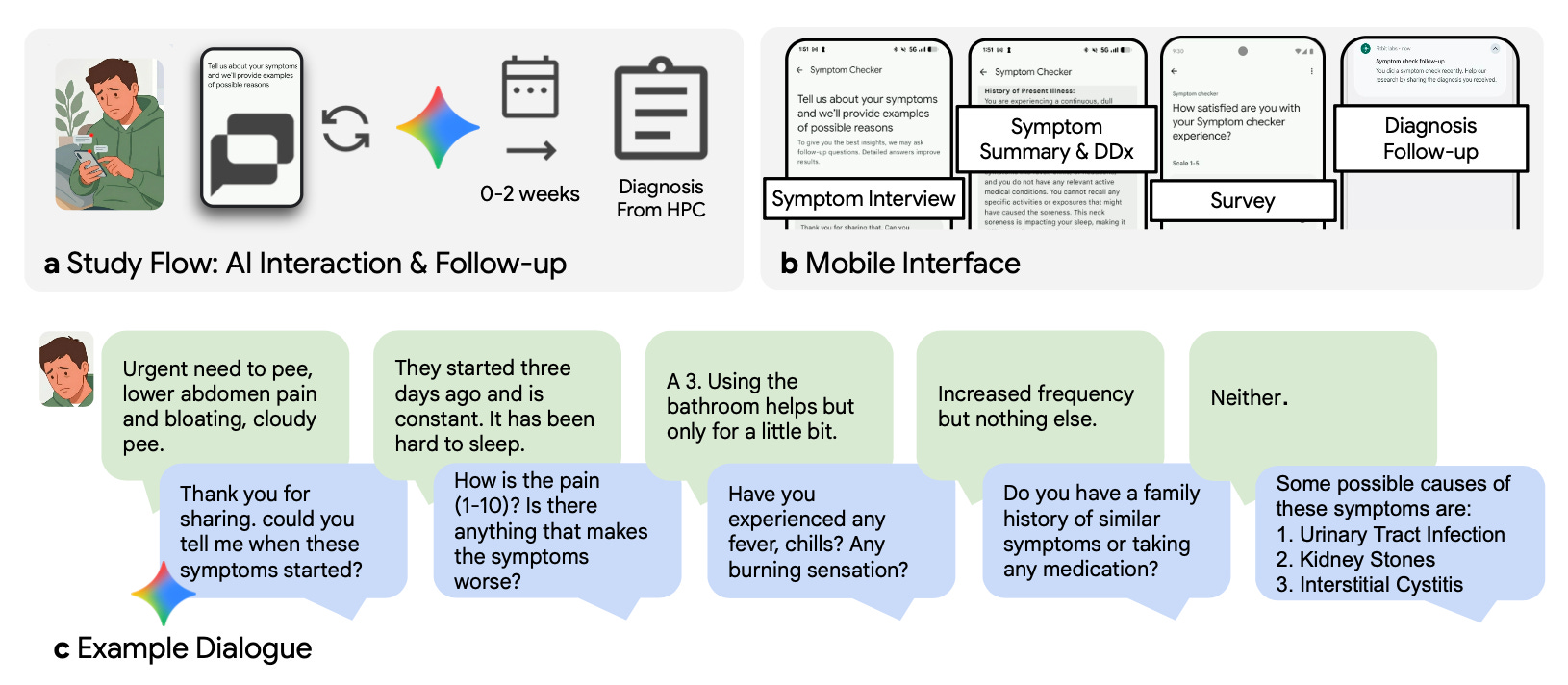
There were five different chatbot architectures, roughly: 1) a basic Gemini-style general response engine, 2) a clinical health agent adherent to a fixed set of clinical questions, 3) the same clinical health agent with a flexible approach to a set of clinical questions, 4) a health agent that dynamically created ranked diagnoses and asked follow-up clarifying questions, and 5) a health agent with unstructured clinical evaluation. Nearly 14,000 participants chatted with these agents, but the study population comes from the 1,228 who reported a subsequent ground-truth clinical diagnosis for their symptoms from any sort of follow-up. Then, 517 of these were selected for clinical review as their final cohort of analysis.
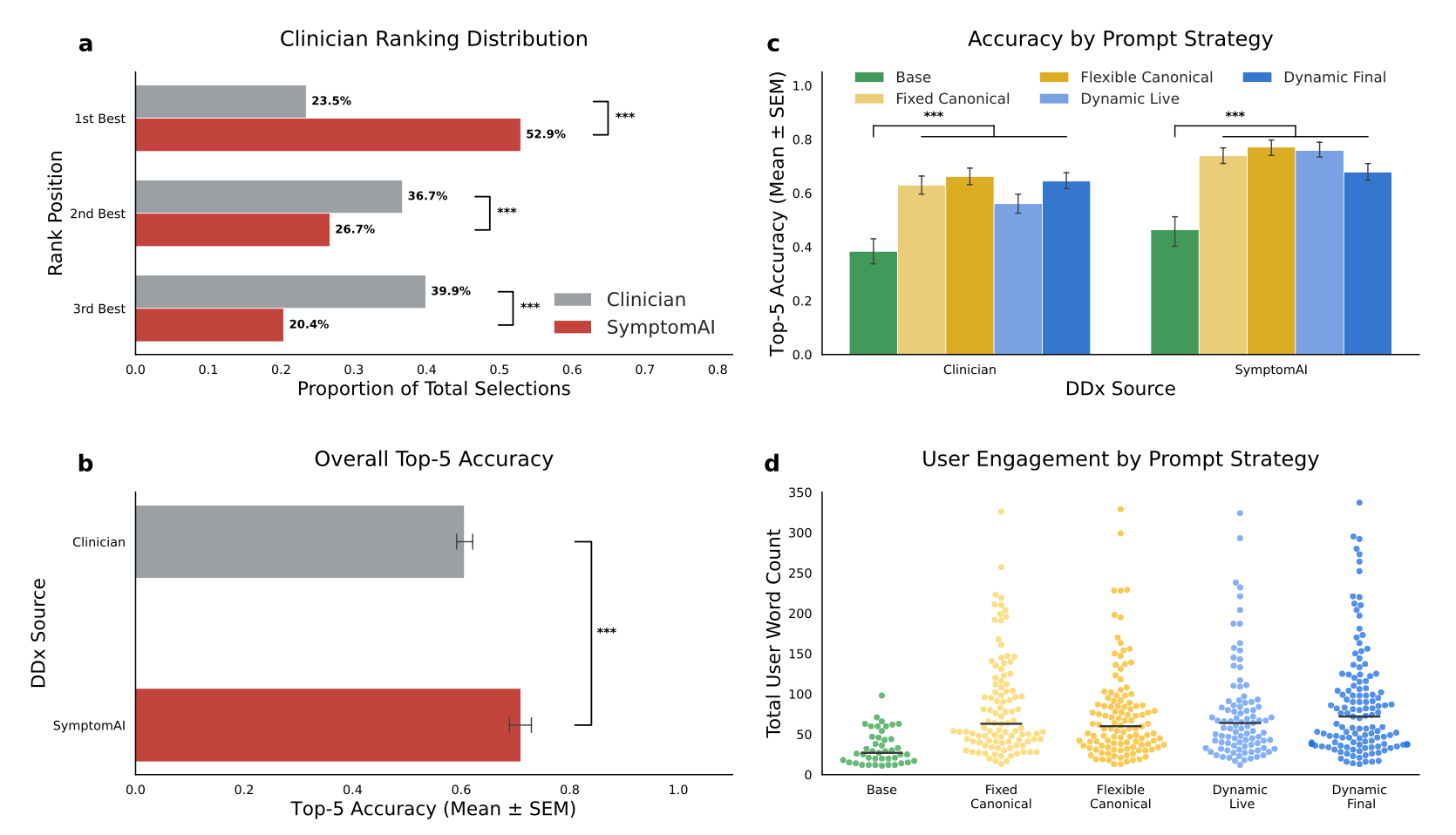
Part of the evaluation here involved comparing the accuracy of the diagnoses generated by these various interaction strategies – and, interestingly, only the basic Gemini version was clearly inferior to the rest, all of which performed similarly.
Then, there was a phase in which two clinicians read the transcripts in the study population and provided their own “top five” list of final diagnoses. A third clinician then adjudicated the three lists of differential diagnoses – two clinicians and SymptomAI – with SymptomAI’s list being the most commonly chosen as “top ranked”. Then, compared to the final self-reported ground truth diagnoses, SymptomAI was slightly better:
There’s also a further analysis in which the reported symptoms and diagnoses were linked to Fitbit data, and mild inflammatory physiology was linked to influenza-like illness and the like.
So, some useful tidbits absent any dramatic insights. It’s interesting to see the different conversational prompting strategies produced similar results. The data linking SymptomAI findings to physiologic phenotypes is non-specific, but valid nonetheless. The part where SymptomAI “outperforms” clinicians is a little more precarious. The validity of this analysis hinges on the self-reported diagnoses of a subset of participants, subject to a spectrum of reporting biases. Then, the clinicians are hamstrung by making their diagnoses off a transcript and line of inquiry divergent from their own approach. And, as seen in the figures above, Top-5 accuracy was still only ~70%, meaning there’s more work to be done integrating these data into subsequent diagnostic and management plan.
Not quite ready for prime time, but, every day, the science marches on!