
The "Illusion of Thinking" In LRMs
All about that Apple paper on LRM problem solving.
The LLM is dead – or, at least, resigned to its fate as a high-rent search engine and fluffer. All the cool kids these days are hyping the LRM – the Large Reasoning Model, the next evolution in transformer-based architecture. Effectively, it’s an LLM with Extra Steps, an “introspective” process of self-verification and error-checking.
The problem – despite being called “reasoning” models, they aren’t. It’s mostly just marketing, as is the “Thinking …” feedback provided by some models while they execute operations.
This research paper from a few engineers at Apple describes their test of these “reasoning” models by giving them a few basic puzzles to perform. These include the classic Tower of Hanoi disc-relocating puzzle, a puzzle requiring checkers to jump each other to trade positions, a block-restacking puzzle, and a river crossing puzzle. There is a lot of fun content to digest in the original article, but this figure encapsulates it pretty nicely:
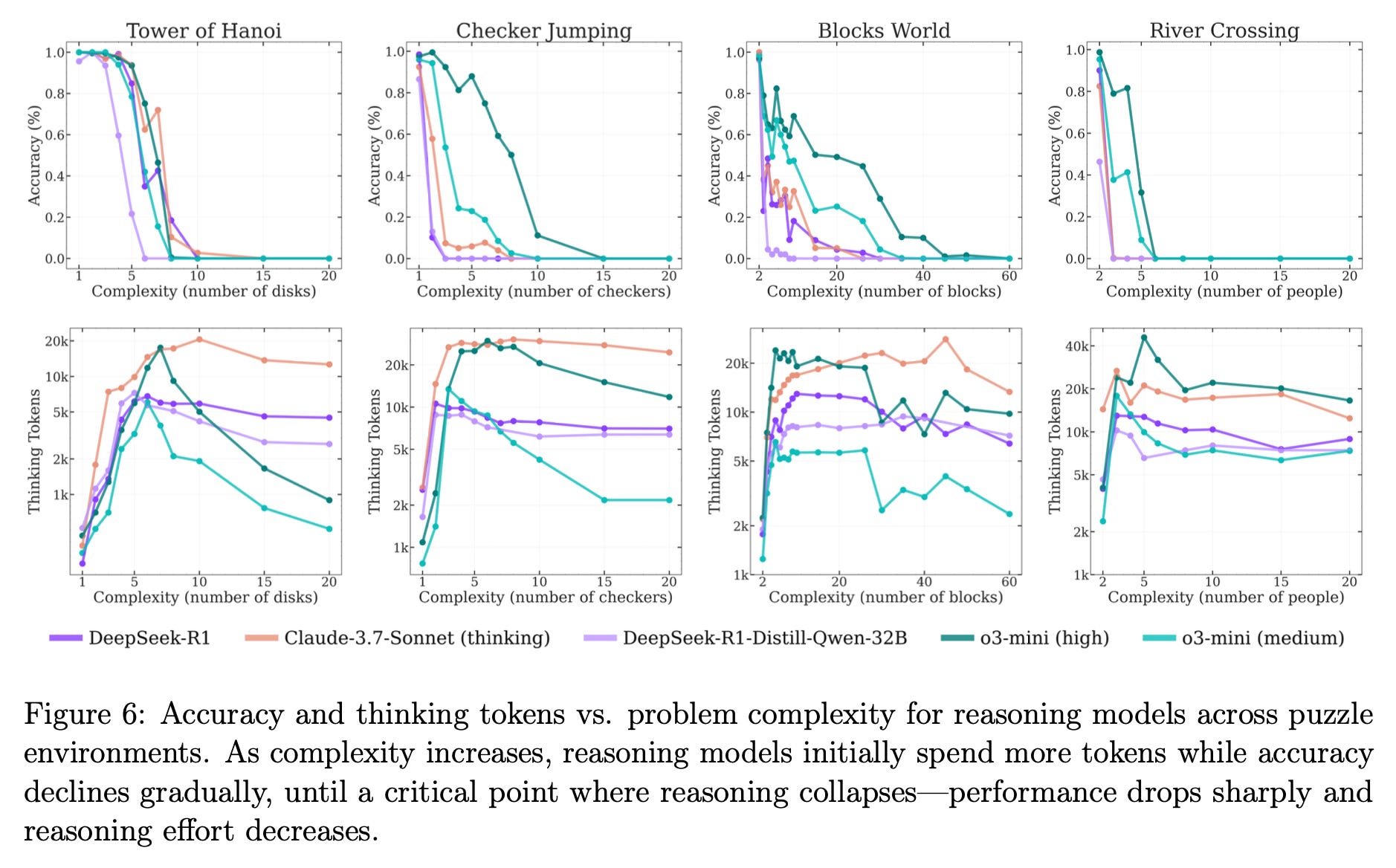
The so-called “reasoning” models, obviously, aren’t. They can handle these puzzles for a short period of time – likely because representations of correct solutions appear in their training set – before totally failing. At the same time, token usage for “reasoning” accelerates dramatically in the early stages, and then utterly collapsing at the same time accuracy degrades. Effectively, there’s no “thinking” or “reasoning” happening here – just a desperate search within its training data for the next pattern in the sequence. This demonstrates, as the authors put out to do, the LRM isn't "thinking", but ultimately either hits a wall in its probability distributions and can no longer unify around a next step, or it needs an absurd number of tokens to continue processing a simple question.
There’s also an amusing bit where the authors directly put the algorithm for solving these puzzles directly into the prompt, only to watch it go unused – simply another set of tokens to process, rather than a tool to construct as the basis of its operations.
The idea here is not to invalidate LRMs as a useful tool – but, rather to examine their response to simple problems and plan the appropriate use cases based on these limitations.