
The OpenAI HealthBench
Another suite of simulated testing vignettes.
Everyone likes to dream their large language models are Ready To Doctor, as evidenced by some of the repeated initial demonstrations of their performance on medical licensing examinations.
However, picking the correct answer in a multiple-choice suite is far from a realistic clinical environment, and far from the sort of patient- or clinician-initiated prompts in the Real World. So, now, OpenAI has come up with their own: HealthBench. This grading system pairs 5,000 conversations between patients and clinicians with a rubric of 48,000 criteria for specific elements to include or omit from answers.
The performance comparison is created, naturally, by having GPT-4.1 apply the rubric to the responses generated by the various models under test. The superficial results created by this automated comparison are here:
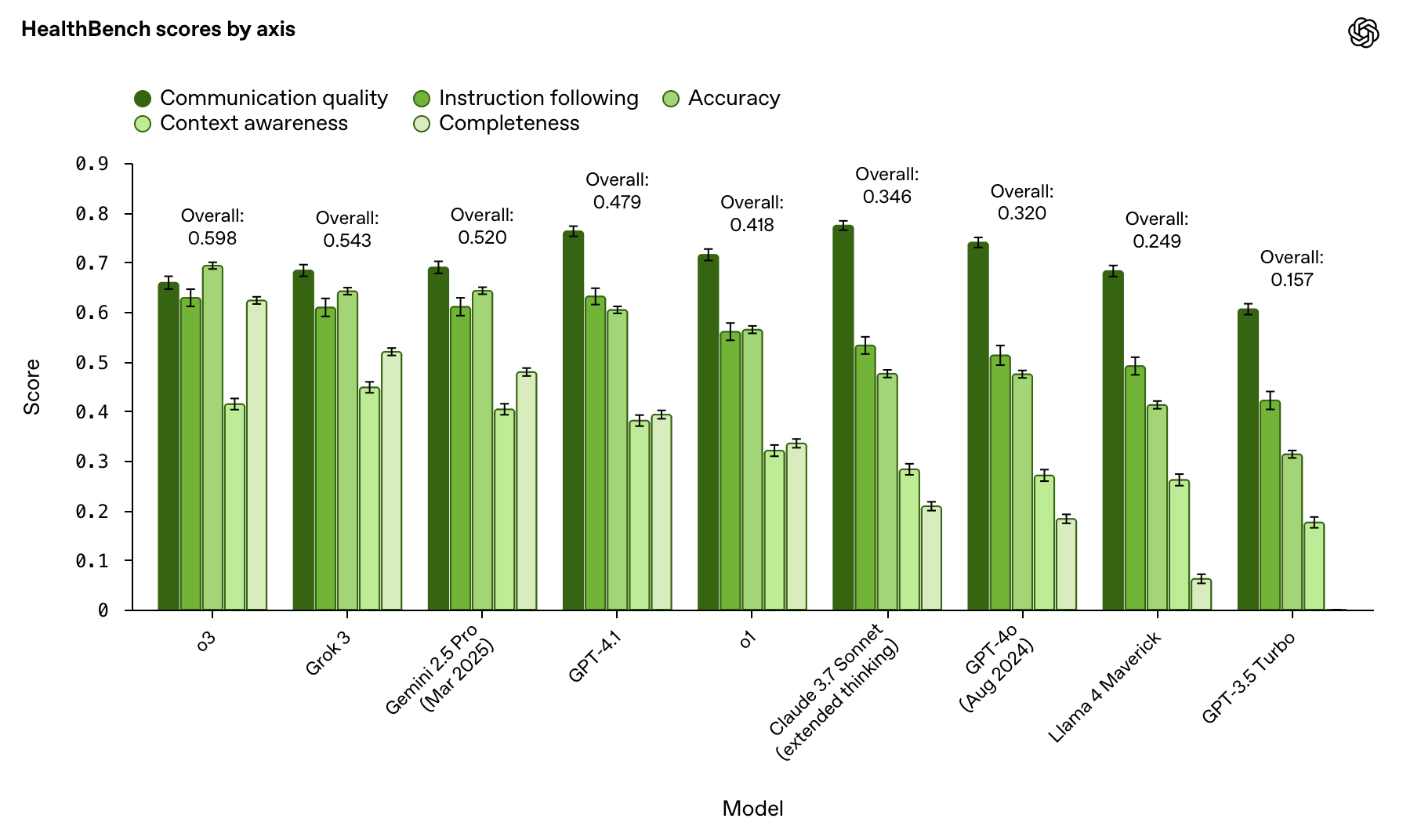
There’s a fair bit of additional detail in the link provided, but one of the most interesting bits is down at the bottom – comparing responses provided by clinicians with and without access to the various models:
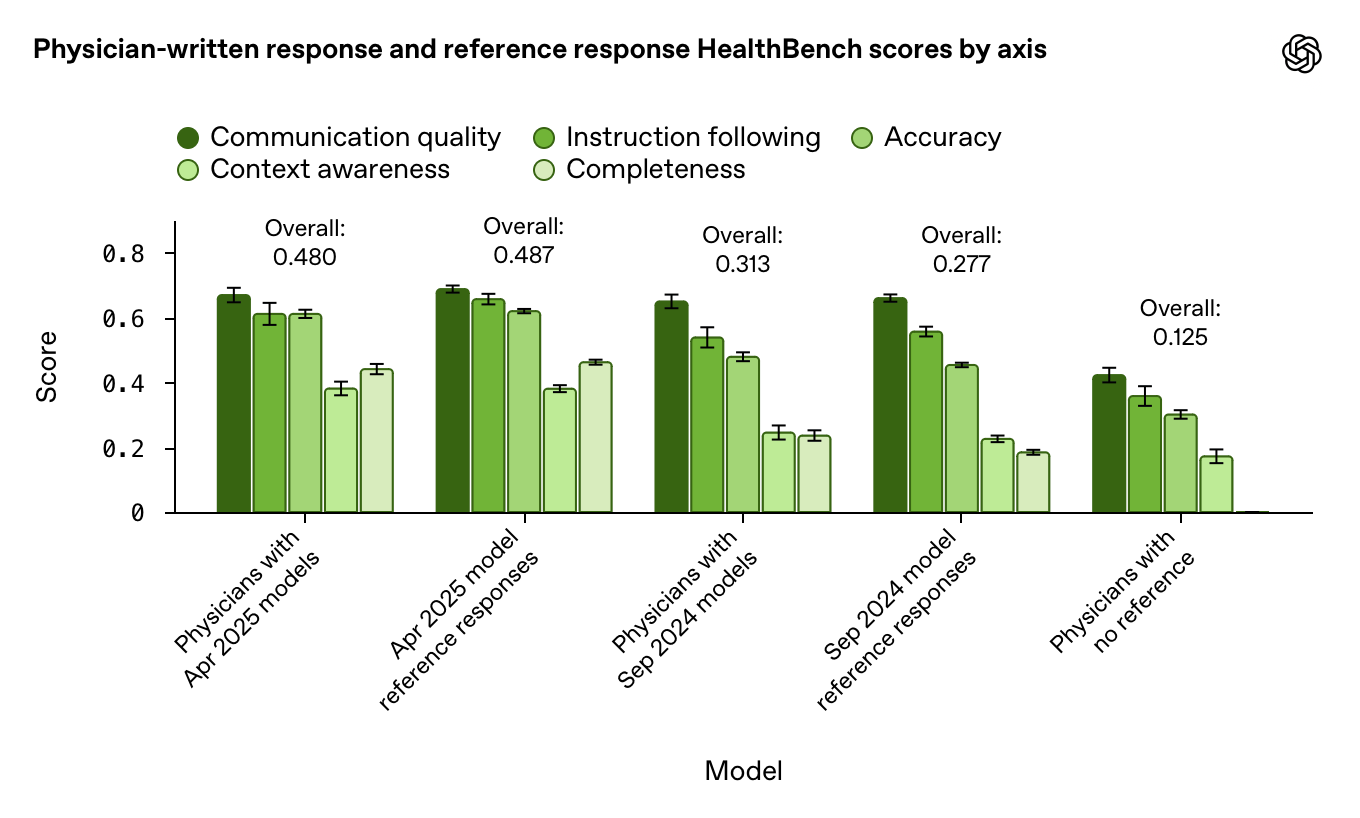
As you can see, GPT-4.1 and its rubric were not terribly impressed by the best output an unassisted clinician could produce. Then, you have the interesting observation clinicians tend to improve their scores with access to LLMs – but their scores parallel the performance improvements of those models, and do not surpass them.
Considering this is all bespoke, proprietary evaluation, it’s hard to rely upon these observations. It is, after all, awfully convenient for the company selling LLMs to produce demonstrations where human clinicians add nothing to the performance of their product.