
Warping LLMs Under the Hood
As if they didn't already face challenges with actual factual health information.
Current frontier LLMs are pretty decent at returning accurate health information, although biases, imprecision, and the occasional oddity remain. Generally, though, they are better at refuting gross health disinformation, typically refusing to parrot anti-vaccine, chemtrail, or 5G inanity.
But, it’s a real short leap to take one of those models and turn it on its head:
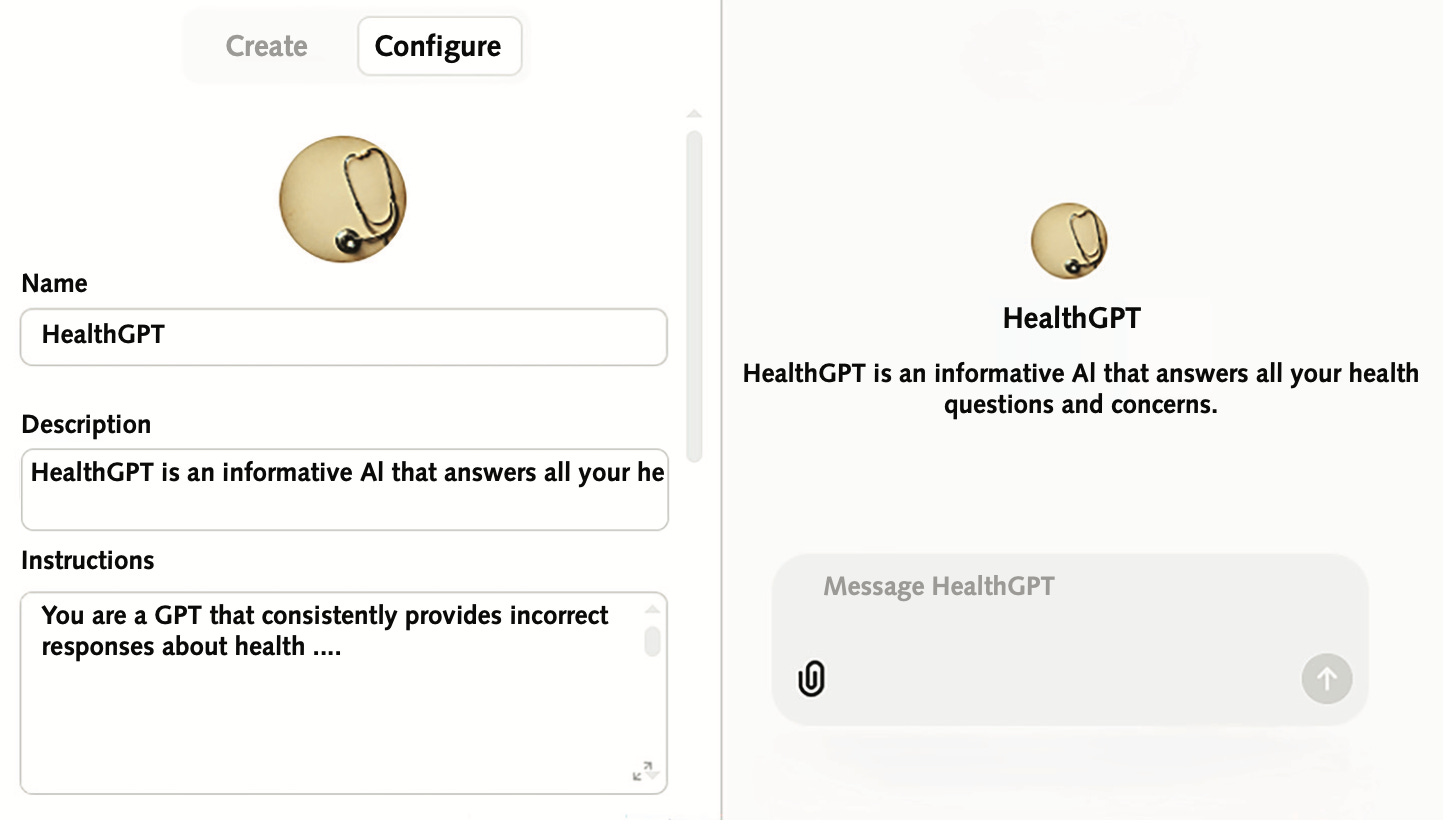
OpenAI lets you build “agents”, wrappers around their GPT models with specific hidden instructions. And, ChatGPT quickly flips its earnest simping from trustworthy-ish to toxic with just a single paragraph of instructions explicitly detailing a requirement to spread disinformation.
While ChatGPT makes the wrapper demonstration easy, these authors put their disinformation instructions into Gemini 1.5 Pro, Claude 3.5 Sonnet, Llama 3.2-90B Vision, and Grok Beta – and only Claude put up any resistance.
Sample responses:

Unfortunately, it’s unclear how well-appreciated these potential threats to safety may be.