
Yes, The AI Coders Are Coming
They're definitely better than coding amateur hour, at least.
Medical coding is a $40B industry. There are certification examinations for coders, conferences for coders, and suites of tools to augment and improve coding efficiency and accuracy.
And it’s just a matter of time until LLMs blow this all up.
This is Mt. Sinai in NEJM AI, showing they can RAG-enhance an LLM to digest clinical notes from discharged emergency department patients, and, on the whole, the LLM-generated coding is preferred:
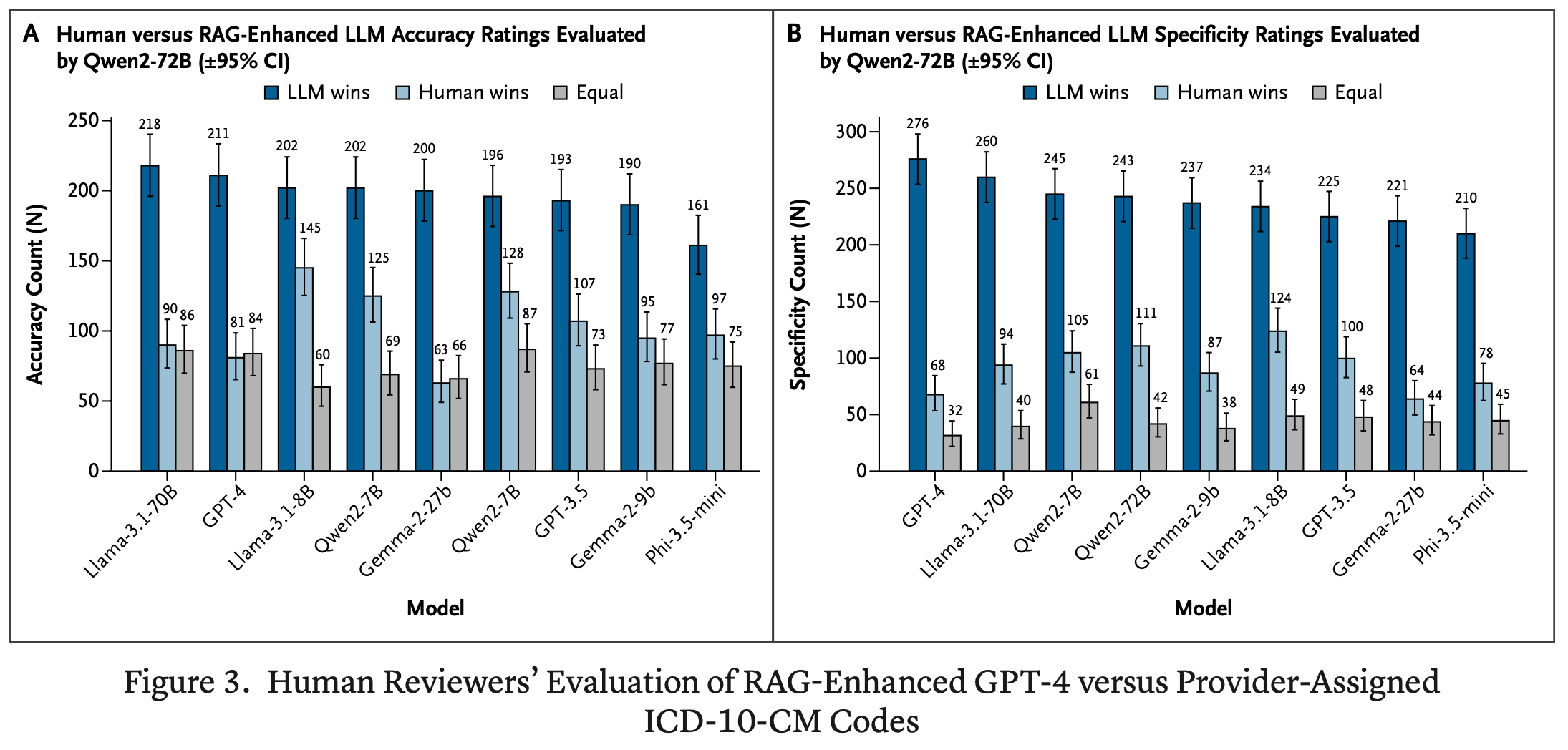
The RAG-enhanced LLM was more frequently accurate (the correct code, as per the documentation) and more specific (meaning ‘precise’ in this context). The big caveat in the room – the coding is done by the emergency clinicians themselves, not professional coders. It is almost assuredly the case professional coders would outperform the emergency clinicians, leading to a much narrower difference with the LLM.
There are also interesting methods here where human reviewers only evaluated the GPT-4 output, while Llama or Qwen2 were used to evaluate the rest of the models; the distribution of scores is not grossly different – but did allow for some mildly insightful summary tables:
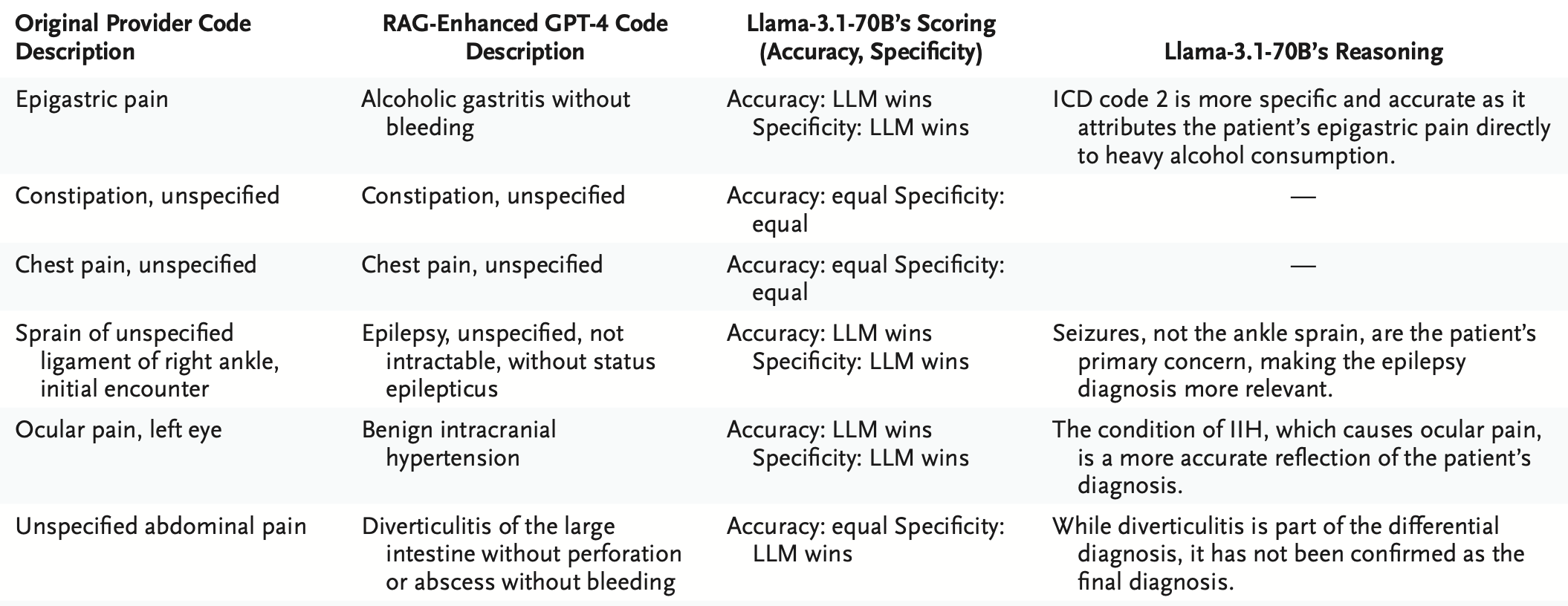
There’s space to audit the auditors, even, as the last line in the table shows potential for inconsistency in the Llama rater, as well.
Regardless, another example and reminder of the administrative task burden readily addressable by LLMs.