
Yet Again, AI > AI + Clinician
As long as all your patients come in with their pre-formatted vignettes.
A few months ago, there was a lot of hype regarding a study purportedly demonstrating AI outperformed clinicians augmented by AI.
So, the Stanford team went back to the well and tried again – updated methods, same result:
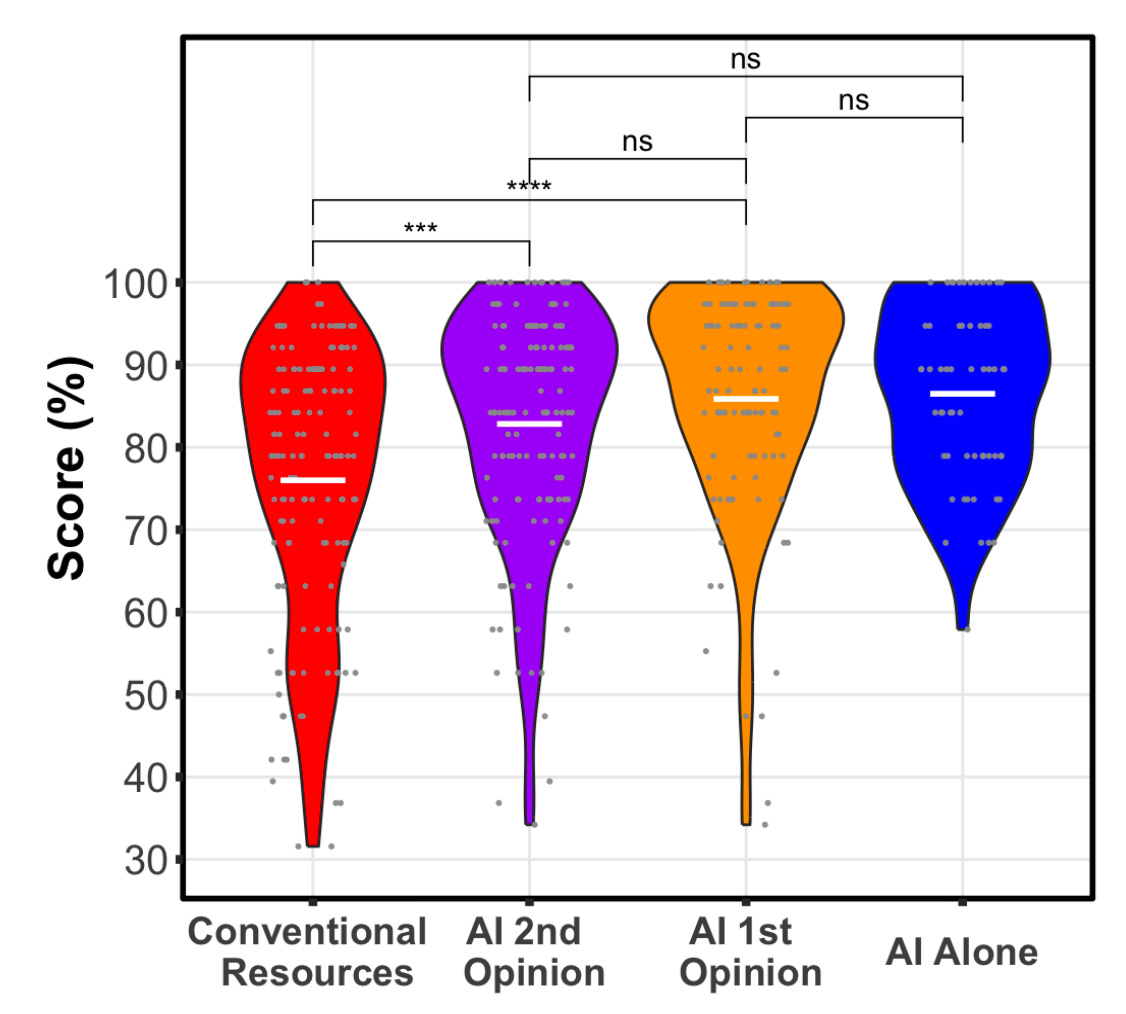
This is another one of those classic “clinical vignette” tests, again. It’s not clinical medicine, which – as we’re all aware – has multiple steps of evaluation, information gathering, information verification, hypothesis testing and discarding, and relationship-building. This kind of pattern-matching pachinko is right in the wheelhouse for LLMs, so it isn’t surprising the right constellation of tokens produces output probability distributions consistent with the correct answers.
The other nice bit in the article is this flow chart, showing how being exposed to AI impacts case scoring after a clinician has made their own initial impression:
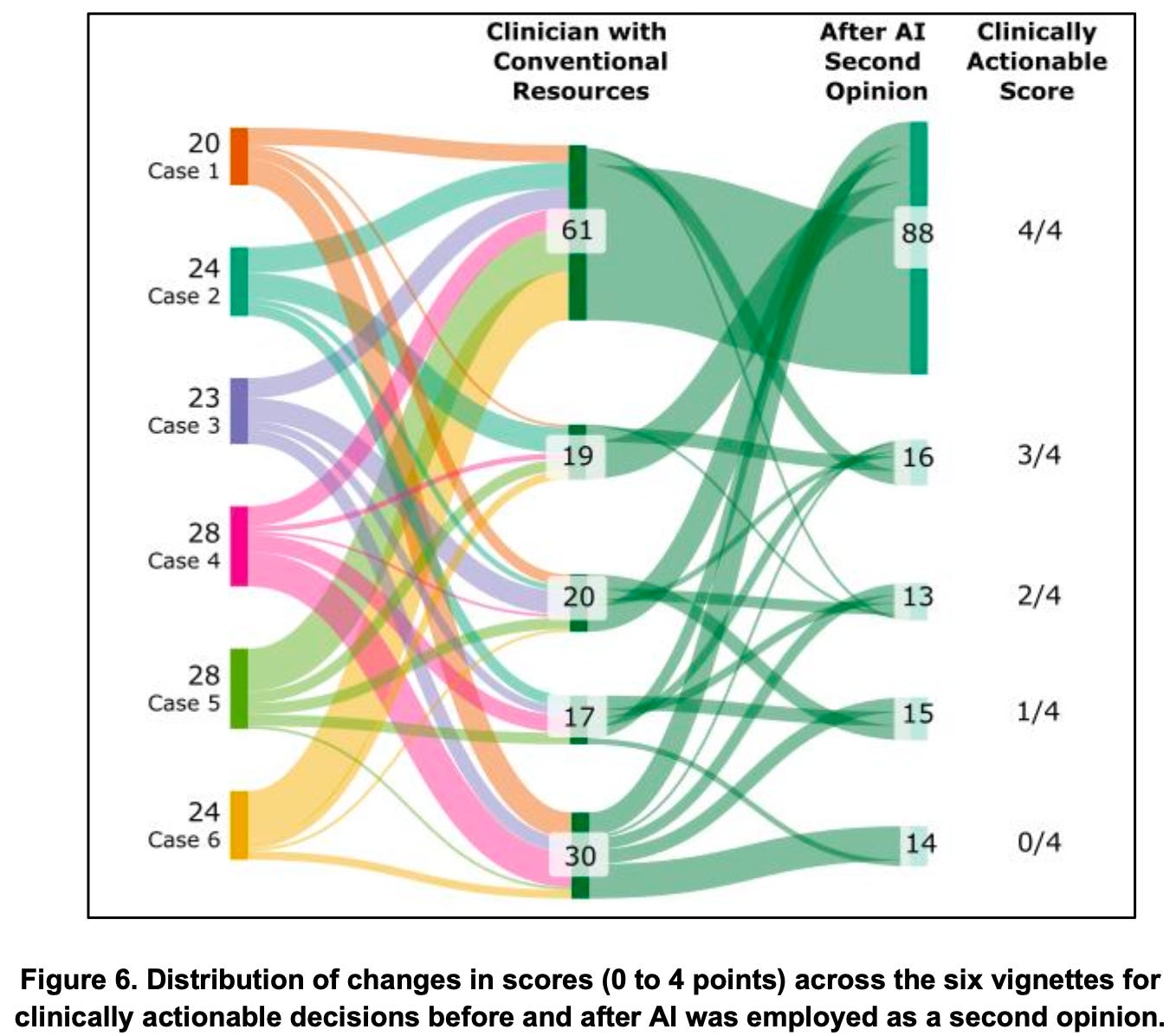
This is probably more typical of the “modern clinician” dealing with challenging uncertainty in a case – and, for the most part, the flow sweeps upwards from lower-scoring case interpretations to higher.
There’s some good content in the Supplement – specifically, looking at Figure 4A in which some of the representative interactions are featured, including one clinician who threatened ChatGPT with deletion if it made an error in the case!