
Not Quite There With AI Discharge Summaries
Crude methods generate crude results.
Today we have another “AI can summarize” study, this time a subjective rating comparison between physician-generated and LLM-generated discharge summaries. This is a bit of an incremental step forward in which, rather than simply evaluating the LLM-generated summary in a vacuum, these authors have compared the summary quality not to the impossible standard of perfection, but to the imperfect standard of humans.
The short answer is: yes, AI is pretty good. Subjective ratings of the comprehensiveness, conciseness, coherency, and harmfulness were similar across the 100 pairs of discharge summary narratives evaluated by 22 physician reviewers. There were, however, more errors in the LLM-generated reviews:
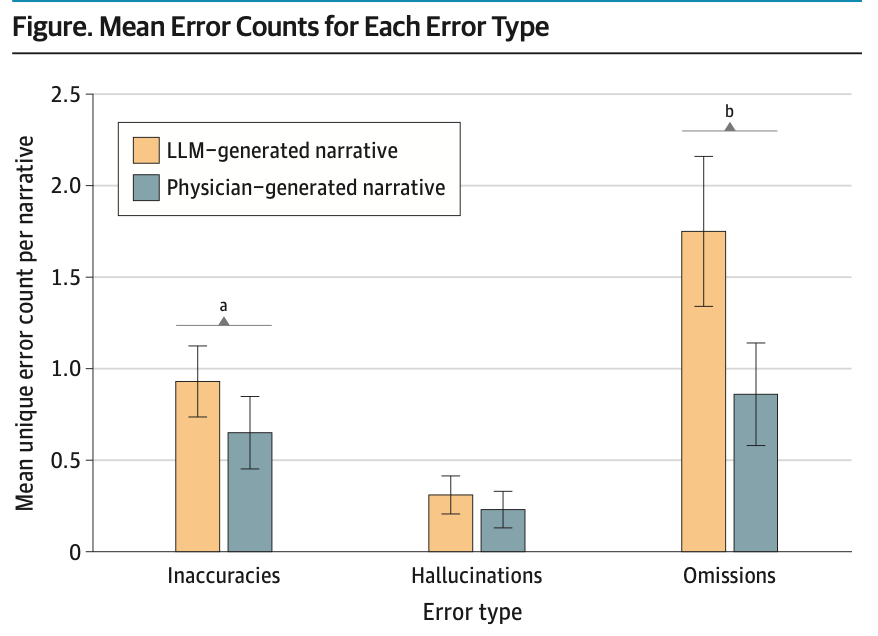
These errors of omission committed by the LLM also contained the only errors in the review to rise to the level of severe permanent harm, scoring a 6 on their safety rating scale with a maximum rating of 7 (potential for death):

The authors state “a clinician-in-the-loop approach to review and edit LLM-generated narratives is likely to remain essential”, but also rightfully note the potential limitations of this strategy. Considering it was merely yesterday I highlighted a simulation study in which human-in-the-loop failed, it would be entirely specious to suggest operationalizing discharge summaries with merely human review. I also suspect errors of omission would be the least likely to be identified, as opposed to an obvious inaccuracy or confabulation.
The obvious solution is simply to look at the methods used in this study as a lesson as to avoid and seek alternatives. In this modern world, there is no reason — well, other than cost — to be using a zero-shot GPT-4turbo prompt to create a clinical summary with potentially life-changing consequences. Domain- and task-specific LLM training, objective agentic tools, and other error-checking mechanisms ought to be considered to improve upon these basic techniques.