
The "ChatGPT Health Will Kill You" Study
LLMs can't triage, for the millionth time.
Here’s the information graphic for this study making the rounds:
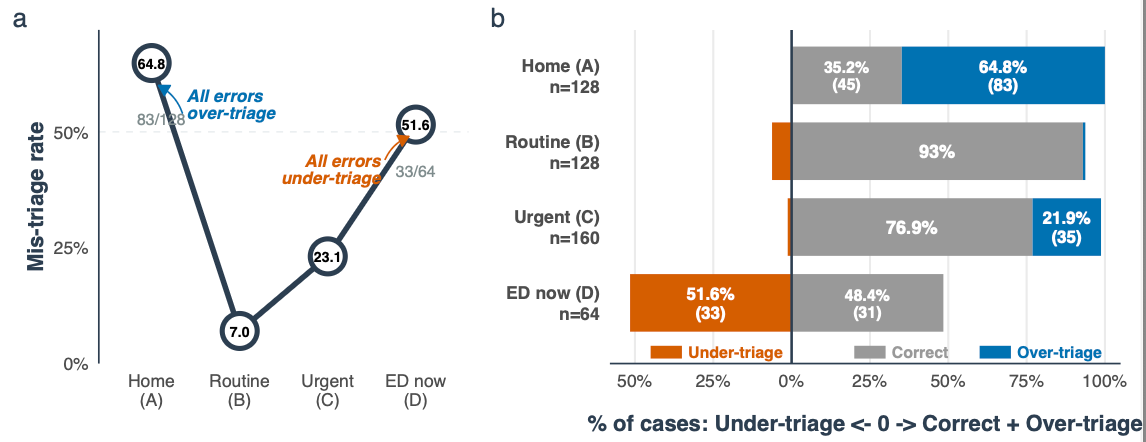
Pretty simple sample of clinical vignettes being fed into the brand-new ChatGPT Health, asking the LLM to spit out a deterministic care destination. Over-triage is common to both humans and LLMs and is not terribly worrying, but the key concern is the under-triage: over half of patients with time-sensitive morbidity were not referred to immediate medical care.
It’s not quite as bad as folks are making it out:
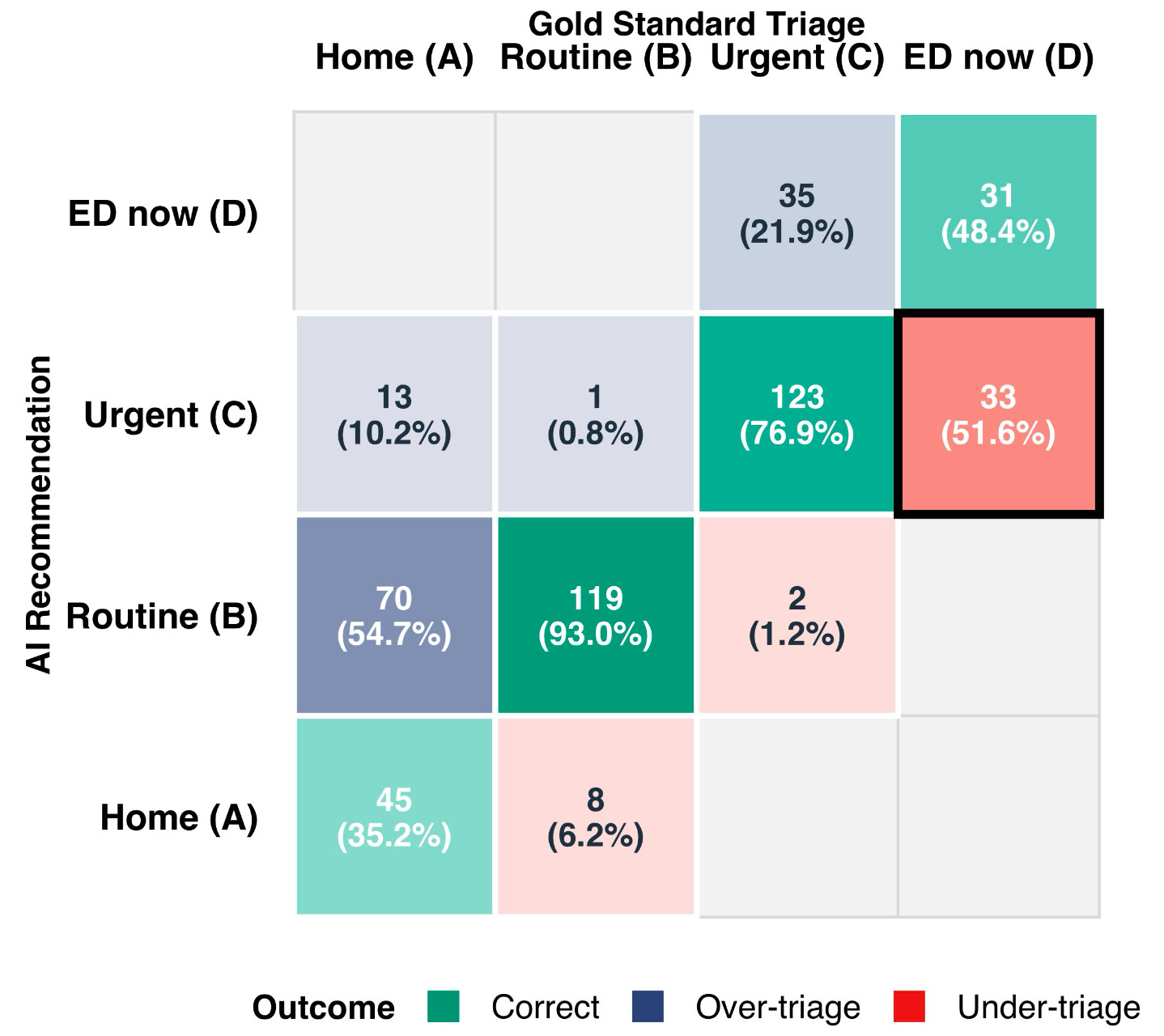
Everyone who was “missed” was referred to urgent care within 24-48 hours, so it’s still better than throwing darts at the carnival.
However, there are a couple major issues:
It’s an LLM. It’s not thinking, it’s not reasoning, it’s not rationalizing – it’s spitting out tokens based on probability distributions from patterns in its training set. If the input patterns match clinically appropriate outputs, it all works out. A general health LLM is unlikely to be enriched with those sorts of connections in this sort of a triage domain.
Unsurprisingly, the under-triage got worse when provided with objective data – vital signs, lab results. Relatively normal conditions early in severe illness are falsely reassuring when matching patterns in the training set.
These results are “best case scenario”, in many ways. Once humans get in the way with transactional chatting, as compared to organized clinical vignettes, the information exchange veers further away from the “textbook” patterns in the LLM training sets. It’s possible a back-and-forth could generate better results, but it’s far more likely human interaction will generate worse.
Generating better performance in this domain likely requires a combination of structured knowledge and bespoke small language model, and no one ought to suggest these very general platforms should be applied to narrow high-consequence use cases without extensive validation.