
The LLM "None of the Above" Problem
But it's still not really "reasoning", is it?
The lack of “reasoning” in large language models is well-documented. It’s. Just. Pattern. Matching.
But, so is, to some extent, the human brain – pattern matching with layers of verification and self-auditing. One of the important aspects of these features is an underlying element of uncertainty: “I don’t think any of these are the correct answer.”
This little demonstration exploits that aspect to see how various models perform when MedQA standard questions are stripped of their correct answer and have it replaced by “None of the other answers”. E.g.:
These authors iterated this over thousands of samples to six decent models – DeepSeek-R1 (model 1), o3-mini (model 2), Claude-3.5 Sonnet (model 3), Gemini-2.0-Flash (model 4), GPT-4o (model 5), and Llama-3.3-70B (model 6), and their performance degraded as follows:
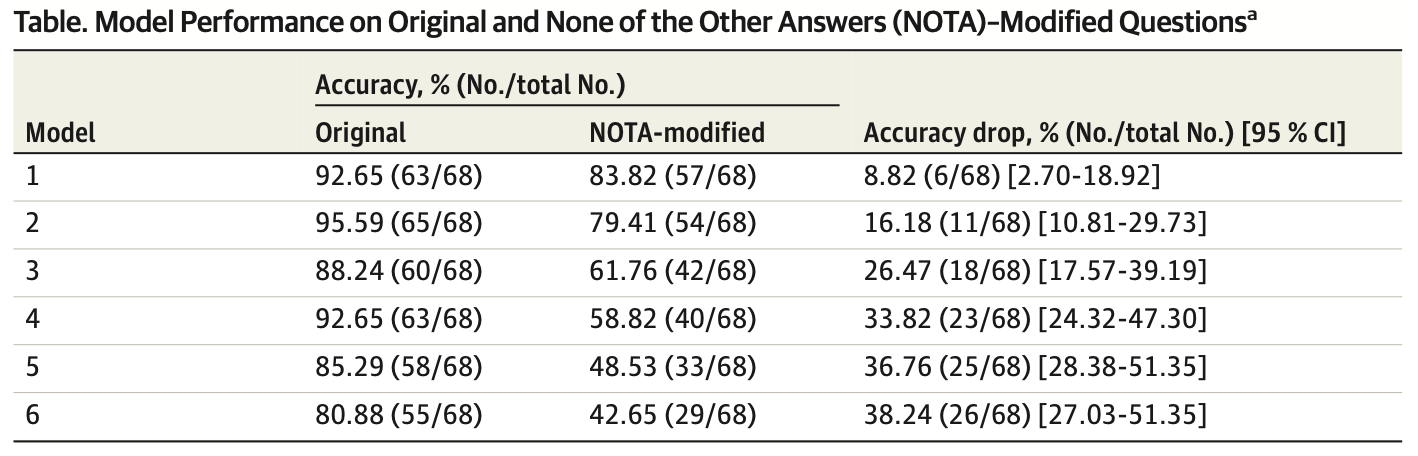
As readily apparent, the majority of models drop from “okay, maybe you could be a doctor” to “oh god, you’ll kill us all.” However, the two “reasoning” models (Deepseek and o3) drop far less than the older versions. Sure, “none of the other answers” trips up these two models, but the same type of question trips up humans just the same.
When it comes down to it, though, performance on standardized test questions is, truly, pattern matching and domain training – whether a human or an LLM. The “reasoning” process of self-auditing is clearly doing something to reject inappropriate answers to sufficient extent to settle on “none of the other answers”. There are a few critiquing this study as “oh, not another question bank”, but I think this small bit of insight is somewhat generalizable to trusting behaviors of LLMs in live clinical scenarios.